NextcloudにLocalAIを導入してみる(GPU)
ConoHaVPSのL4サーバーでLocalAIをテストした時のメモです。
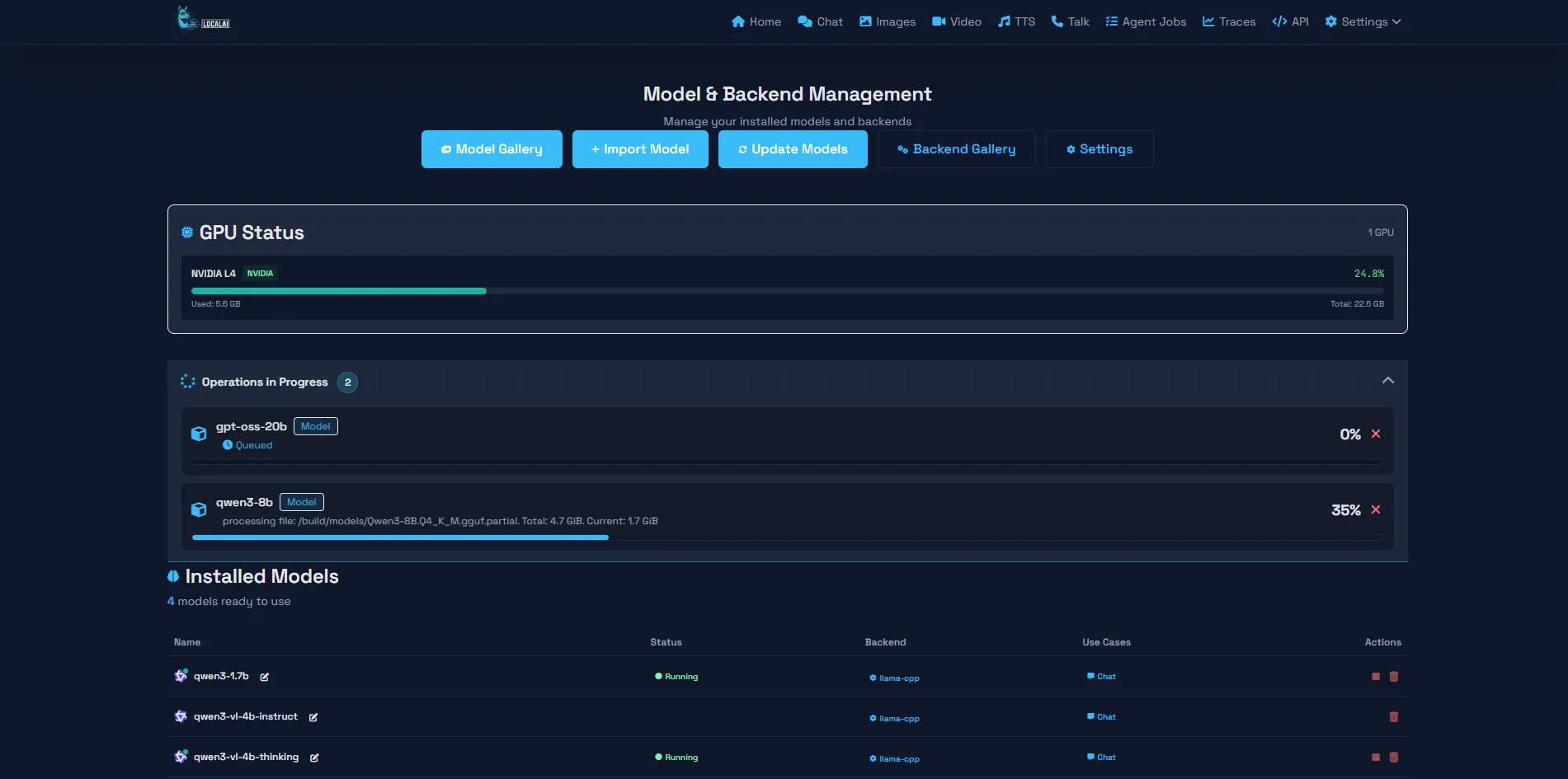
VPSのスペックは
| 項目 | 詳細 |
|---|---|
| OS | Ubuntu 22 |
| CPU | 4Core |
| メモリ | 16GB |
| GPU | NVIDIA L4 24GB |
CPU版にも書いてますがNextcloudにわざわざローカルAIを導入するメリットはあるのか不明です。
Nextcloud AIようにGPUサーバー分の価格が増えるわけですからね・・・
またはGPUサーバーを借りてそこにNextcloudも構築するかですね。
あと今回、少し雑にまとめてます。
必要ならCPU版も見てください。
更新しておく
更新を念のためかけておきます(VPS借りたばっかでもあるので)
sudo apt -y update
sudo apt -y upgrade
Dockerをインストールする
パッケージの更新をする
sudo apt -y install \
apt-transport-https \
ca-certificates \
curl \
gnupg \
lsb-release
Docker公式のGPG鍵を追加する
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | \
sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
最新の安定版(stable)を取得する。
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
インストールする
sudo apt -y update
sudo apt -y install docker-ce docker-ce-cli containerd.io
Nvidiaのドライバーインストール
NVIDIA Container Toolkit のリポジトリ取得
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey |
sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
ドライバとツールキットのインストール
sudo apt -y update
sudo apt -y install ubuntu-drivers-common nvidia-container-toolkit
最適なドライバを自動インストール
sudo ubuntu-drivers autoinstall
Dockerの設定をGPU用に更新
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
ドライバ認識のため一度再起動
再起動必須です。
sudo reboot
再起動後の確認
以下のコマンドで
sudo nvidia-smi
以下のように表示されるはずです。
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 590.48.01 Driver Version: 590.48.01 CUDA Version: 13.1 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA L4 Off | 00000000:00:06.0 Off | 0 |
| N/A 41C P0 27W / 72W | 0MiB / 23034MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
LocalAIの構築 (Docker)
今回もCPU同様に/opt/localaiで作業します。
sudo mkdir -p /opt/localai/models
cd /opt/localai
docker-compose.yml の作成
sudo vi docker-compose.yml
以下を貼り付ける(APIキーなどは変更してください)
私はcuda12版を使いますが13もありますので好きなのを
nvidia-smiの結果的には13がインストールされているので13のほうがいいかも
services:
local-ai:
image: localai/localai:latest-gpu-nvidia-cuda-12
container_name: local-ai
restart: always
ports:
- "8080:8080"
environment:
- MODELS_PATH=/build/models
- THREADS=3 # VPSのコア数に合わせながら調整
- GPU_LAYERS=-1 # -1にすると、可能な限りすべてGPUに乗せます
- CONTEXT_SIZE=4096 #GPUなのである程度好きなサイズに調整してください
- API_KEY=momijiina #好きなキーに変更してください。Nextcloud等で使うキーです。
volumes:
- ./models:/build/models
# ↓GPUをコンテナに渡すために必要な記述
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: ["/usr/bin/local-ai"]
起動する
sudo docker compose up -d
バックエンドをインストールする
CPU版と同じのいれてますがもしかしたらダメかもです。
これ入れた後、管理パネルからモデル入れちゃったのでテストしないんですよね・・・
必要ならバックエンド一覧から確認を・・
バックエンド一覧を取得する
momijiinaはAPIキーです。
インストール可能なバックエンドを表示できます。
curl -s http://localhost:8080/api/backends \
-H "Authorization: Bearer momijiina" | sed -n '1,200p'
llama-cppをインストール
momijiinaはAPIキーです。
localhostとポートも自由に変更してください。
curl -s -X POST "http://localhost:8080/api/backends/install/localai@llama-cpp" \
-H "Authorization: Bearer momijiina"
コマンドでモデルファイルをダウンロードする
モデル一覧を取得する
取得してみました多すぎて見てられないです(管理パネル推奨とします)
curl -s http://localhost:8080/models/available \
-H "Authorization: Bearer momijiina" | grep "id"
qwenだけ見やすくしたとしても無理ですね。
もっと細かく指定しないとだめですね。
curl -s http://localhost:8080/models/available \
-H "Authorization: Bearer momijiina" | grep "qwen"

ダウンロードする
curl -X POST http://localhost:8080/models/apply \
-H "Content-Type: application/json" \
-H "Authorization: Bearer momijiina" \
-d '{
"id": "qwen3-1.7b"
}'
Nginxを設定する(例)
Nginxは最新版がインストールされている前提
sudo vi /etc/nginx/conf.d/localai.conf
これは例です。
調整してください
server {
listen 80;
listen [::]:80;
server_name localai.momijiina.com;
server_tokens off;
return 301 https://$host$request_uri;
}
server {
listen 443 ssl;
listen [::]:443 ssl;
http2 on;
server_name localai.momijiina.com;
ssl_certificate "/etc/letsencrypt/live/localai.momijiina.com/fullchain.pem";
ssl_certificate_key "/etc/letsencrypt/live/localai.momijiina.com/privkey.pem";
ssl_session_cache shared:SSL:10m;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_session_timeout 10m;
location / {
proxy_pass http://localhost:8080;
proxy_read_timeout 600s;
proxy_connect_timeout 600s;
proxy_send_timeout 600s;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_buffering off;
proxy_cache off;
proxy_http_version 1.1;
chunked_transfer_encoding on;
}
}
他はCPU版をみてください
CPU版と同じなのであとはカットしますがスクリプト作成は絶対必須です。