WSLでllm-scalerのvllmもテストする(動作不可)

Ubuntu25版を必要なら見てください(こちら)
LM Studioより速度が速くなるとかはなかったです。
一人で使うならLM Studioでよさそうです。
一応ですがWSLでの実行はあまりお勧めしないです。
パラメーターを細かく指定しないとすぐエラーです。
WSLは私の知識範囲外です。
もうめんどくさいので触りたくないですね。
※2026年2月12日に再修正
※2026年2月14日に最終検証しましたが動作は難しいと判断しました。
最終修正とします
WSLにvllmを入れる
今回はUbuntu 24が一番新しいので24です。
推奨は25のしかもデスクトップ版みたいですね。
ドライバーインストール
公式を一応みてください
dgpu-docs-intel
sudo apt-get update
sudo apt-get install -y software-properties-common
sudo add-apt-repository -y ppa:kobuk-team/intel-graphics
sudo apt-get install -y libze-intel-gpu1 libze1 intel-metrics-discovery intel-opencl-icd clinfo intel-gsc
sudo apt-get install -y intel-media-va-driver-non-free libmfx-gen1 libvpl2 libvpl-tools libva-glx2 va-driver-all vainfo
sudo apt-get install -y libze-dev intel-ocloc
sudo apt-get install -y libze-intel-gpu-raytracing
base-toolkitをインストール
公式を見てください
base-toolkit
Ubuntu25ではわかりませんが24では少し更新しないとパッケージは見つかりません。
公開鍵の取得
wget -O- https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB \
| gpg --dearmor | sudo tee /usr/share/keyrings/oneapi-archive-keyring.gpg > /dev/null
リポジトリの追加
echo "deb [signed-by=/usr/share/keyrings/oneapi-archive-keyring.gpg] https://apt.repos.intel.com/oneapi all main" \
| sudo tee /etc/apt/sources.list.d/oneAPI.list
インストール
終わったらrebootかけてください
sudo apt update
sudo apt install intel-oneapi-base-toolkit
GPUの認識確認(強制認識)
level-zeroを認識させる必要があるのでさらに追加
source /opt/intel/oneapi/setvars.sh --force
ln -sf /usr/lib/wsl/lib/libze_loader.so.1 /usr/lib/x86_64-linux-gnu/libze_loader.so.1
ln -sf /usr/lib/wsl/lib/libze_loader.so.1 /usr/lib/x86_64-linux-gnu/libze_loader.so
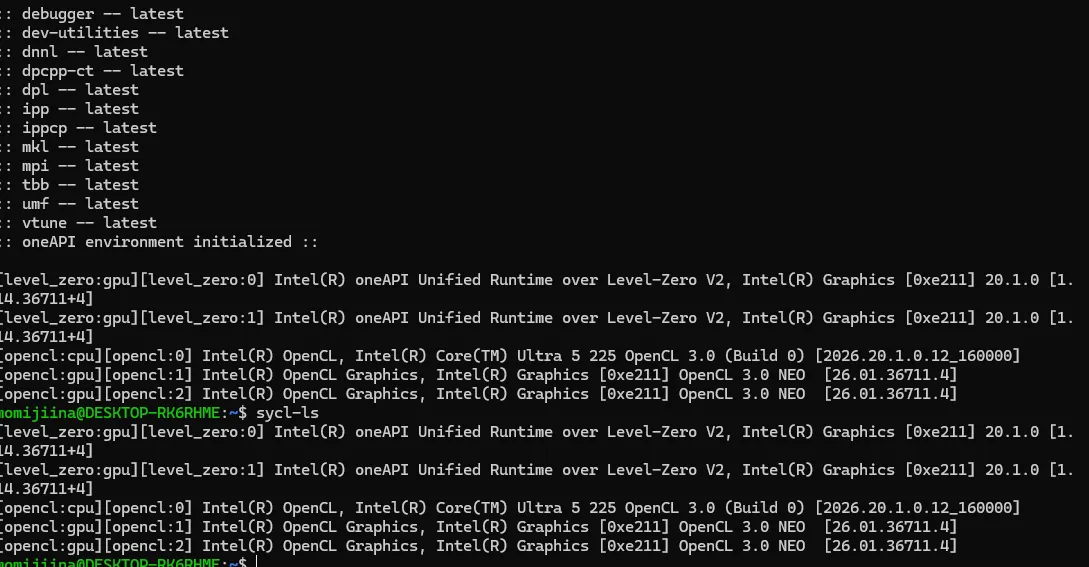
sycl-ls
さらに追加(無理やりlevel-zeroを出してるので間違えてるかも)
export ONEAPI_DEVICE_SELECTOR=opencl:1,2
export VLLM_TARGET_DEVICE=xpu
export VLLM_XPU_BACKEND=OPENCL
export LD_LIBRARY_PATH=/usr/lib/wsl/lib:$LD_LIBRARY_PATH
ldconfig
unset ONEAPI_DEVICE_SELECTOR
unset SYCL_DEVICE_FILTER
sycl-ls
vllmをdockerで起動する
使うバージョンは最新(1.3)ですが必要があれば変更してください。
バージョン下げた方が安定してるかも
一覧
sudo docker run -it --name my-vllm \
--shm-size 16g \
--privileged \
--device /dev/dri:/dev/dri \
-v /usr/lib/wsl:/usr/lib/wsl \
-e LD_LIBRARY_PATH=/usr/lib/wsl/lib \
--entrypoint /bin/bash \
intel/llm-scaler-vllm:latest
GPUの認識確認
勝手にコンテナに入るはずなので以下を実行する
結局、level-zeroとかが表示されないのでパススルーできてないかも
export ONEAPI_DEVICE_SELECTOR=opencl:gpu
sycl-ls

モデルダウンロード
huggingface-cli download openai/gpt-oss-20b --local-dir /llm/models/gpt-oss-20b
vllmを実行する
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 \
VLLM_WORKER_MULTIPROC_METHOD=spawn \
vllm serve openai/gpt-oss-20b \
--model /llm/models/gpt-oss-20b \
--served-model-name gpt-oss-20b \
--quantization mxfp4 \
--dtype bfloat16 \
--host 0.0.0.0 \
--port 8000 \
--trust-remote-code \
--gpu-memory-util 0.9 \
--max-model-len 8192
-tp 1
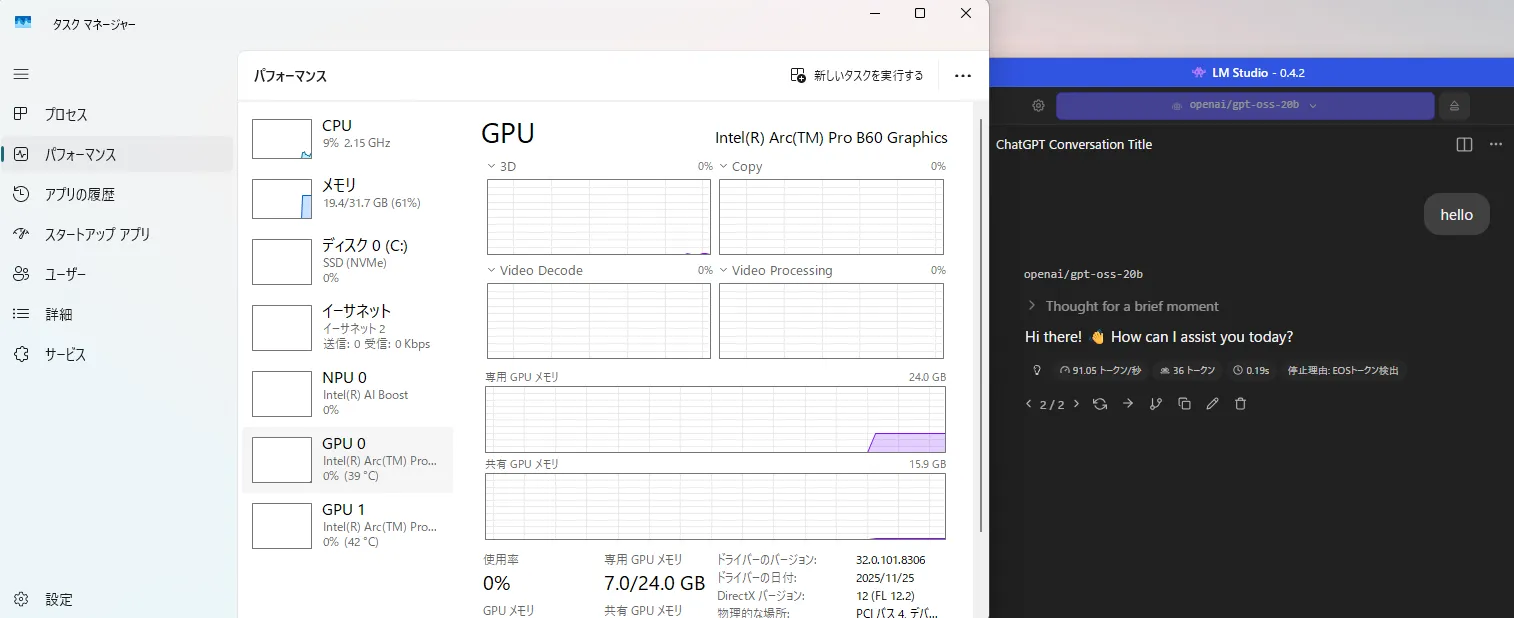
速度確認できず
恐らく現状、特殊な設定をしないとWSLでは動作不可です。
Dockerでlevel-zeroを認識させる方法があればおそらく解決します。
推奨環境 Ubuntu25で実行結果は最高70token/sという結果なので無理にUbuntuでやるよりLM Studioでいいです。
他のとどっちがいいか
私はLM StudioかOllamaを使うことにしました。
今後次第ですが恐らく一人で使うならLM Studioで十分です。
1.3がWSLで動いた方がいたら教えてください。