# 指示: 自律生成型ギアシード・シミュレーター (Procedural Gear-Seed Simulator)
以下の仕様に従い、**1つのHTMLファイル**(HTML/CSS/JavaScript 全て内包)で完全に動作するギアシード・シミュレーターを生成してください。外部ライブラリは一切使用しないでください。Canvas API のみで描画してください。
---
## ■ コンセプト
1つの起点歯車(ドライブ・ギア)から始まり、ユーザーが「追加」するたびにシステムが **自律的に** 噛み合い位置を計算し、歯車が連鎖的に増殖・連動して回転するシミュレーター。
---
## ■ 1. 歯車の幾何学モデル
### 1-1. インボリュート歯形の簡易モデル
各歯車は以下のパラメータで定義する:
- `teethCount` (歯数 N): 8〜60 の整数(追加時にランダム or スライダーで指定)
- `module` (モジュール m): 全歯車で統一値(デフォルト = 8px)。UIスライダーで 4〜16 に変更可。
- `pitchRadius` (ピッチ円半径 r): `r = m * N / 2`
- `addedum` (歯先高さ): `1.0 * m`
- `dedendum` (歯元深さ): `1.25 * m`
- `outerRadius` (歯先円半径): `r + addendum`
- `rootRadius` (歯元円半径): `r − dedendum`
- `toothAngle` (1歯あたりの角度): `2π / N`
- 各歯は台形近似(tooth tip arc → flank line → root fillet arc)で描く。最低でも **歯先の円弧・フランク直線・歯元のフィレット曲線** を含む滑らかな形状にすること。
### 1-2. 描画関数
```
function drawGear(ctx, gear, time) { ... }
```
- `gear` オブジェクトから全パラメータを取得
- 現在の回転角度 `gear.angle` を適用して描画
- 歯面にグラデーション(金属調)を適用
- 中心にシャフト穴(小円)を描画
- 歯車の中心座標 `(gear.x, gear.y)` を基準に `ctx.translate` + `ctx.rotate` で描画
---
## ■ 2. 噛み合い(メッシュ)の自律計算
### 2-1. 新規歯車の配置アルゴリズム
新しい歯車(子ギヤ)を追加するとき:
1. **親ギヤの選択**: 既存歯車リストからランダムに1つ選ぶ(または最後に追加されたものを優先するモード切替可)
2. **中心間距離の計算**: `d = r_parent + r_child`(両ピッチ円が接する距離)
3. **配置角度の探索**:
- 親ギヤの中心から角度 θ (0〜360°) を 1°刻みでスキャンし、候補位置 `(px + d*cosθ, py + d*sinθ)` を算出
- 候補位置が **既存の全歯車と重ならない**(中心間距離 > `outerRadius_existing + outerRadius_child + gap` )ことを確認
- **Canvas境界内** に収まることも確認
- 有効な候補の中から **ランダムに1つ** を選ぶ(有機的な広がりを演出)
- 全角度で配置不能なら、別の親ギヤを再選択してリトライ(最大リトライ = 既存歯車数)
### 2-2. 回転方向と歯の位相同期
- 親ギヤと子ギヤは **逆回転** する
- `child.angularVelocity = −parent.angularVelocity * (parent.teethCount / child.teethCount)`
- **歯の位相合わせ**: 配置時に、親の歯の谷と子の歯の山が正確に噛み合うよう初期角度 `child.initialAngle` を計算する:
```
接触点方向の角度 = atan2(child.y − parent.y, child.x − parent.x)
parent側の歯位置 = (parent.angle + 接触点角度) を toothAngle で割った余り
child.initialAngle = 接触点角度 + π + (半歯分オフセット) − 対応する位相補正
```
この計算により、**アニメーション中に歯が貫通せず、滑らかに噛み合う** こと。
### 2-3. 連鎖的回転更新
- ドライブギア(最初の歯車)のみ `baseAngularVelocity`(UIスライダーで調整可)を持つ
- 各フレームで BFS/DFS により接続グラフを走査し、全歯車の角度を更新
- `gear.angle = gear.initialAngle + gear.angularVelocity * time`
---
## ■ 3. アニメーション・レンダリング
### 3-1. メインループ
```
requestAnimationFrame ベースの60fpsループ
```
- 毎フレーム Canvas をクリアし、全歯車を描画
- 噛み合い線(メッシュライン: 親子の中心を結ぶ薄い線)をオプション表示
### 3-2. 歯車のビジュアル
- **金属調グラデーション**: 歯面に放射グラデーション(#888 → #CCC → #888)
- **歯先のハイライト**: outerRadius付近に薄い光沢線
- **シャフト穴**: 中心に半径 `m * 1.5` の穴(ダークグレー)
- **スポーク**: シャフトから歯元まで 4〜6本のスポーク線(歯数が20以上の場合のみ)
- **影**: 各歯車の下に `ctx.shadowBlur = 8, shadowColor = rgba(0,0,0,0.3)` でドロップシャドウ
### 3-3. 背景
- ダークグレー (#1a1a2e) 〜 ネイビー (#16213e) のグラデーション背景
- 薄いグリッドパターン(50px間隔、rgba(255,255,255,0.05))
---
## ■ 4. ユーザーインターフェース
### 4-1. コントロールパネル(画面左側 or 上部にオーバーレイ)
以下のUIを配置:
| UI要素 | 機能 |
|---|---|
| 「+ ギア追加」ボタン | 歯車を1つ自律追加 |
| 「自動増殖」トグルボタン | ON: 1〜2秒間隔で自動追加 / OFF: 手動のみ |
| 「歯数」スライダー (8〜60) | 次に追加する歯車の歯数を指定 / 「ランダム」チェックボックスON時は無視 |
| 「ランダム歯数」チェックボックス | ON: 歯数を8〜40のランダムに |
| 「モジュール」スライダー (4〜16) | 全歯車の共通モジュール値(変更時は全再計算) |
| 「速度」スライダー (0.1〜5.0) | ドライブギアの回転速度 |
| 「メッシュライン表示」チェック | 歯車間の接続線の表示切替 |
| 「リセット」ボタン | 全消去してドライブギアのみに戻す |
| 「歯車数」表示 | 現在の総歯車数をリアルタイム表示 |
### 4-2. ドラッグ操作
- Canvas上でマウスドラッグすると **ビューポート全体をパン** (移動)できる
- マウスホイールで **ズームイン/アウト** (0.2x 〜 3.0x)
- ズーム中心はマウスカーソル位置
### 4-3. レスポンシブ
- Canvas は `window.innerWidth × window.innerHeight` のフルスクリーン
- リサイズ時に自動調整
---
## ■ 5. データ構造
```javascript
const state = {
gears: [], // Gear オブジェクトの配列
module: 8, // 共通モジュール
driveSpeed: 1.0, // ドライブギアの角速度
time: 0, // アニメーション経過時間
autoSpawn: false, // 自動増殖フラグ
viewport: { x: 0, y: 0, zoom: 1.0 }, // パン・ズーム
};
class Gear {
constructor({ teethCount, x, y, parentIndex, angularVelocity, initialAngle, color }) {
this.teethCount = teethCount;
this.x = x;
this.y = y;
this.parentIndex = parentIndex; // 噛み合い親のindex (-1 = ドライブ)
this.angularVelocity = angularVelocity;
this.initialAngle = initialAngle;
this.angle = initialAngle; // 現在角度(毎フレーム更新)
this.color = color; // アクセントカラー
// 派生値
this.module = state.module;
this.pitchRadius = this.module * this.teethCount / 2;
this.outerRadius = this.pitchRadius + this.module;
this.rootRadius = this.pitchRadius - this.module * 1.25;
}
}
```
---
## ■ 6. 初期状態
- Canvas中央にドライブギア(歯数 = 20, parentIndex = -1, angularVelocity = driveSpeed)を配置
- ドライブギアには特別なマーカー(中心に赤い点 or 金色のリング)をつける
---
## ■ 7. 追加の演出(実装必須)
1. **追加アニメーション**: 新しい歯車はスケール0から1.0へ 300ms の ease-out で拡大して出現
2. **色彩**: 各歯車に HSL カラーを割当(hue = index * 37 % 360 で自動変化)。歯面のグラデーションに薄く反映
3. **パーティクル**: 歯車追加時に噛み合い点から小さな火花パーティクル(10〜20個)を放出。200ms で消滅
4. **歯車情報ツールチップ**: 歯車にマウスホバーすると歯数・回転速度・ギア比を表示
5. **FPSカウンタ**: 右上に小さくFPS表示
---
## ■ 8. コード品質
- 関数は機能ごとに分離(描画 / 計算 / UI / イベント)
- 日本語コメントを主要関数に付与
- ES6+ 構文(class, const/let, arrow function, template literal)
- 即座にブラウザで開いて動作すること
---
## ■ 9. 出力形式
- **単一のHTMLファイル** として出力
- `<style>` タグ内にCSS、`<script>` タグ内にJavaScript
- ファイル冒頭に `<!-- Procedural Gear-Seed Simulator -->` コメント


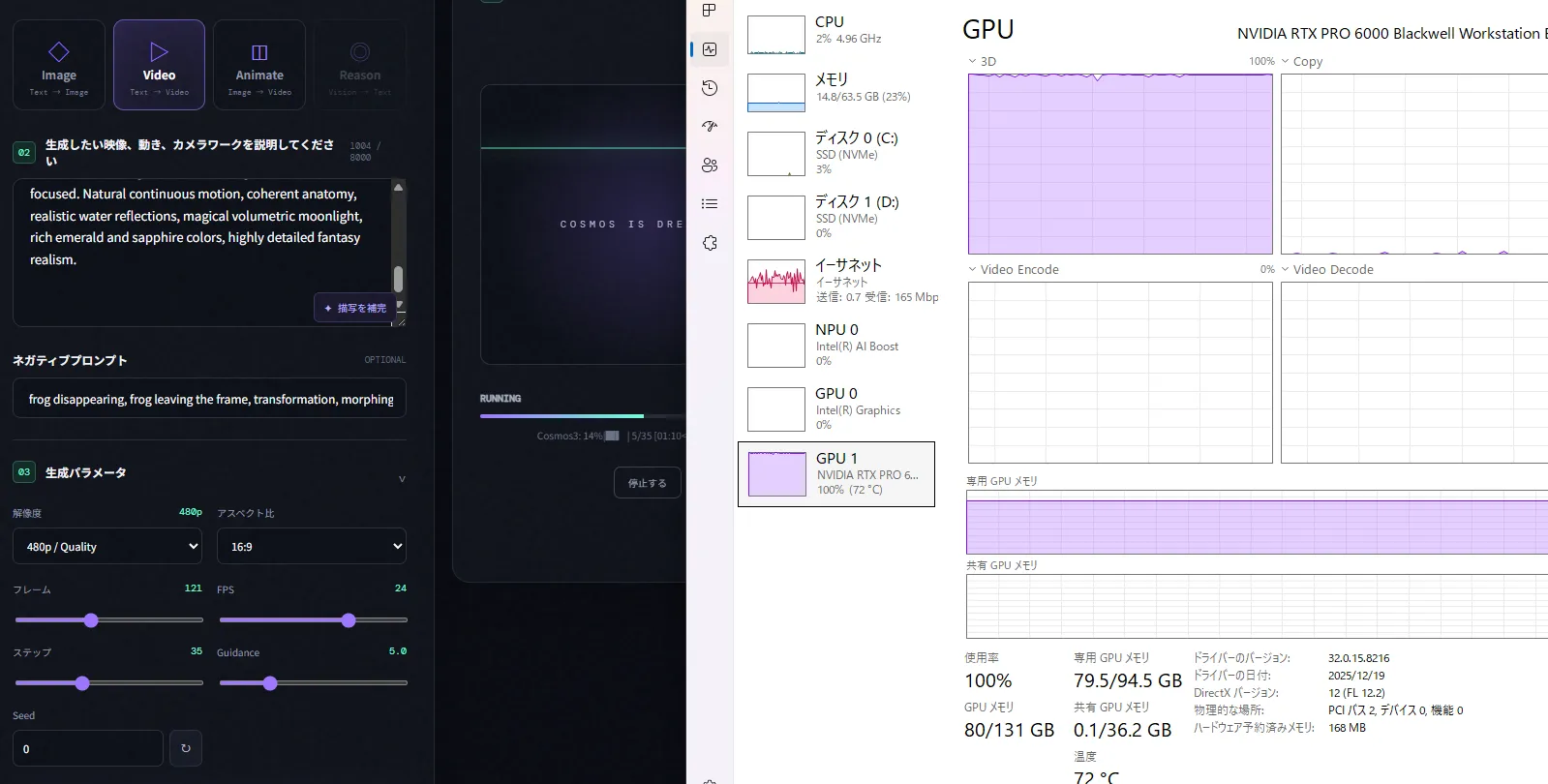
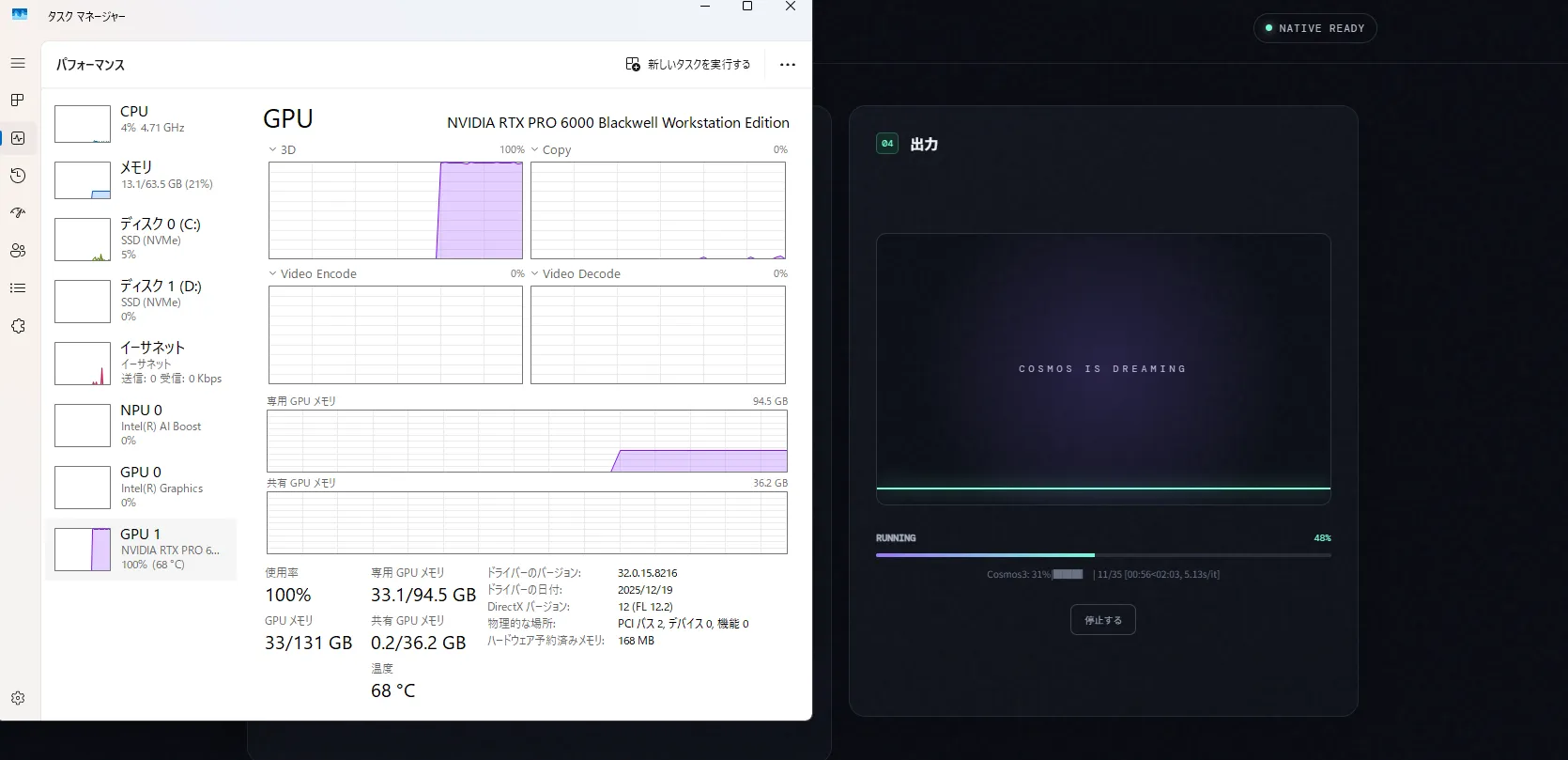 VRAM 33GBははやらないなー
VRAM 33GBははやらないなー

 箱は少しほしかったかも
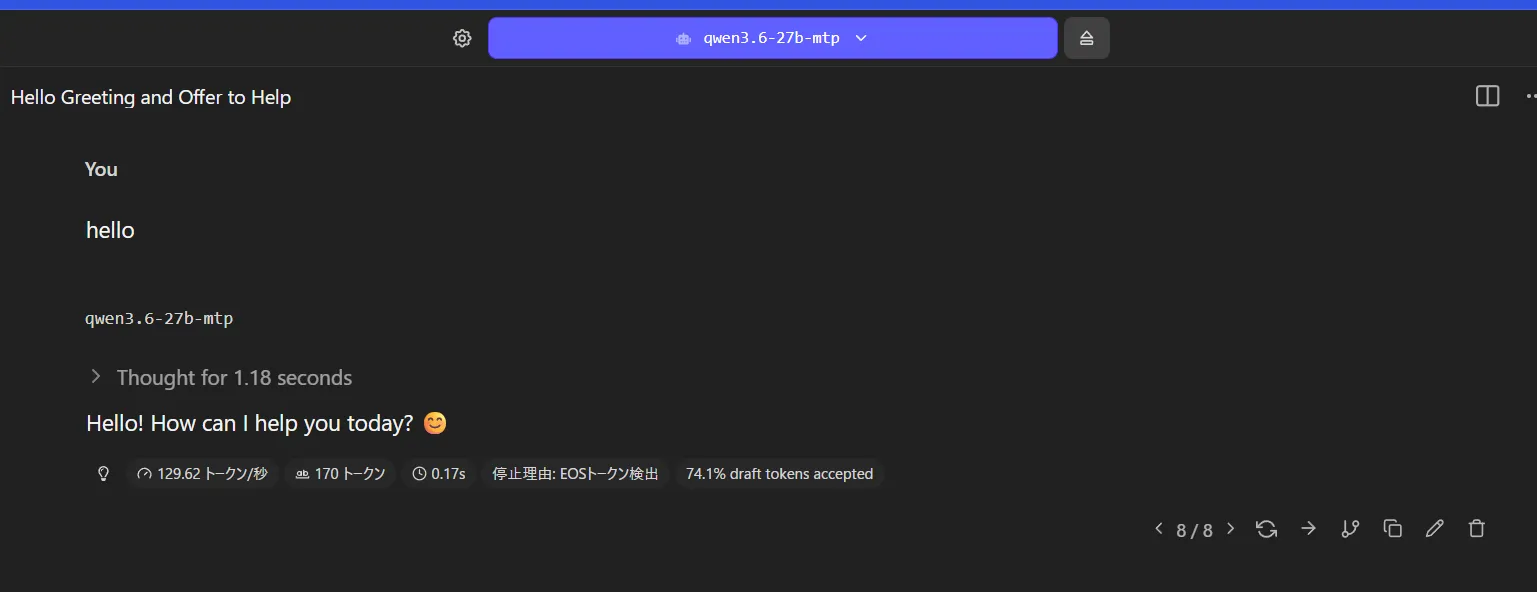
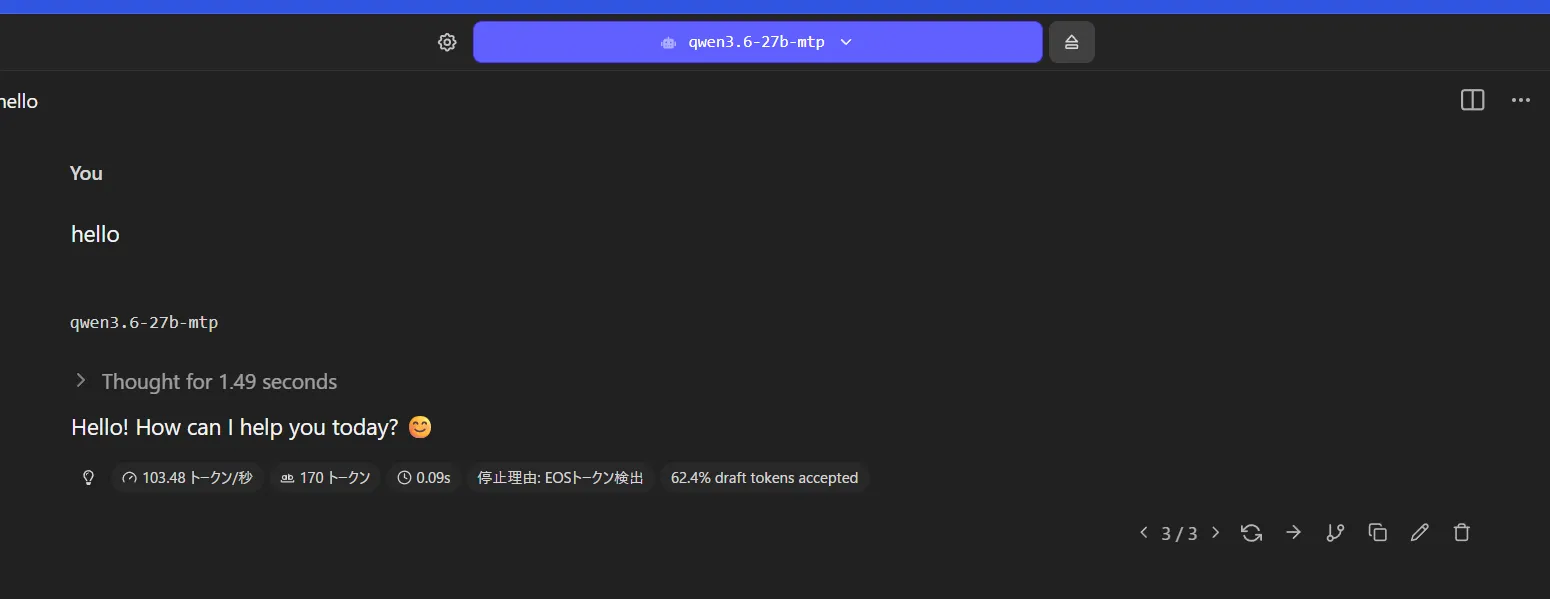
箱は少しほしかったかも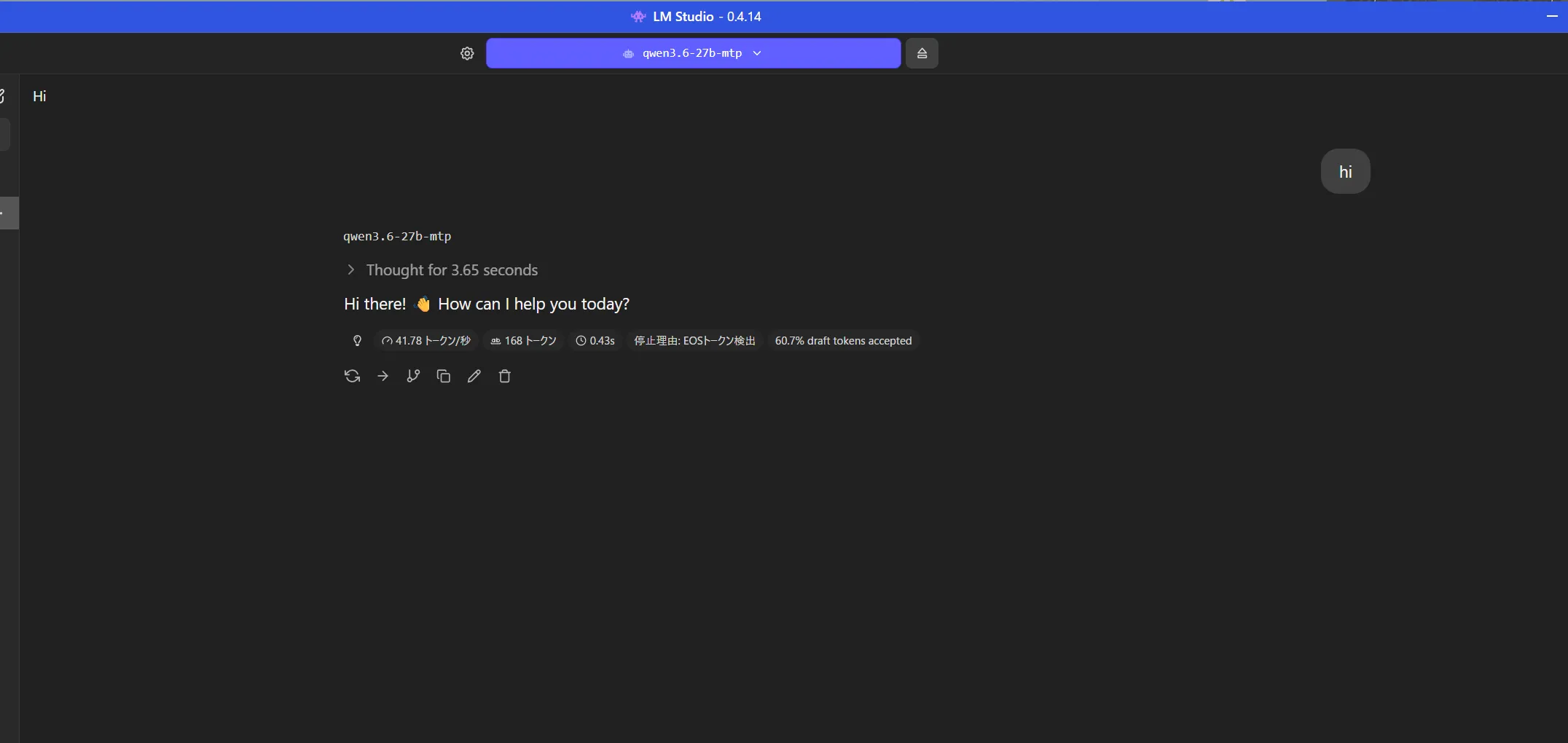 41token/sとまぁ早いですね。
41token/sとまぁ早いですね。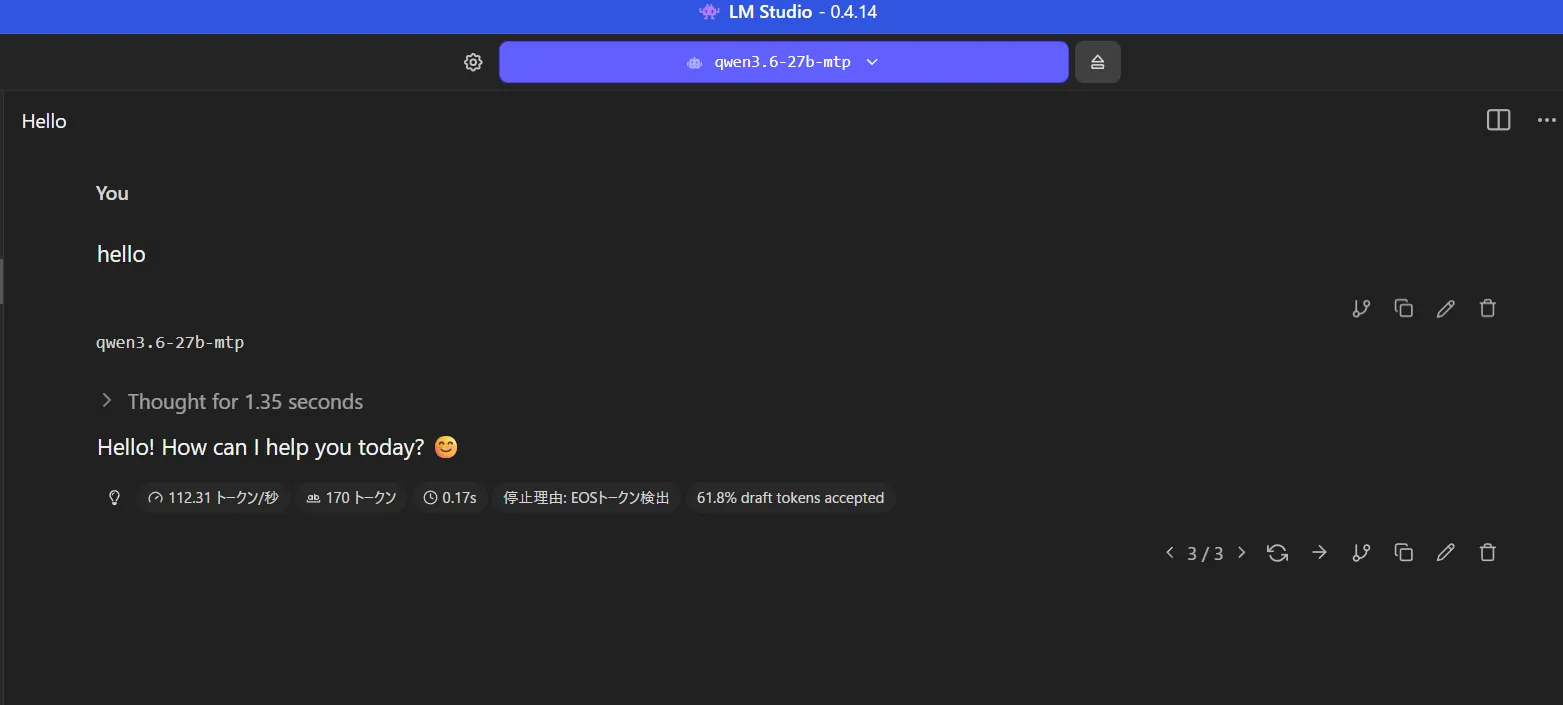
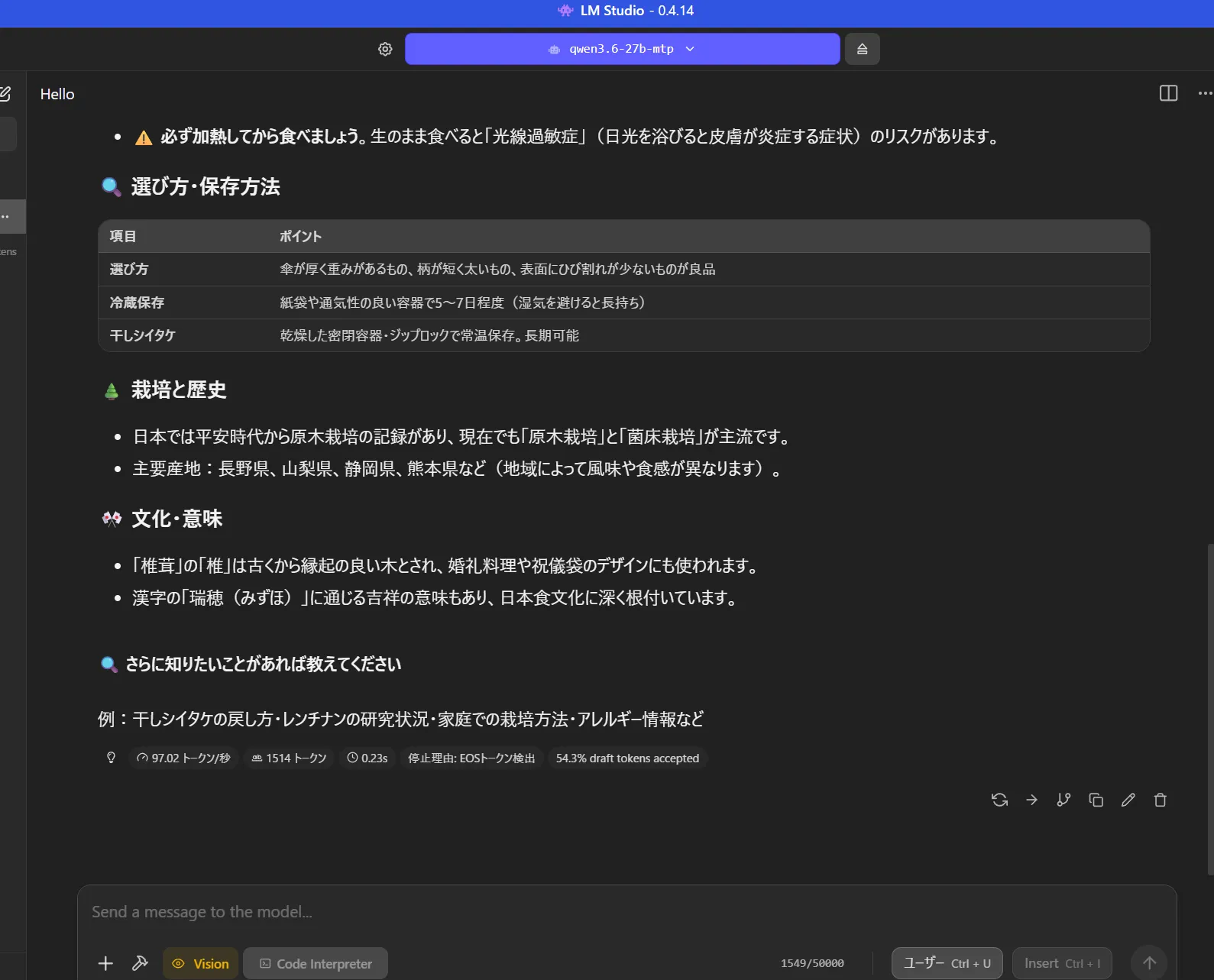
 Vulkanだとちょっと遅いみたい。
Vulkanだとちょっと遅いみたい。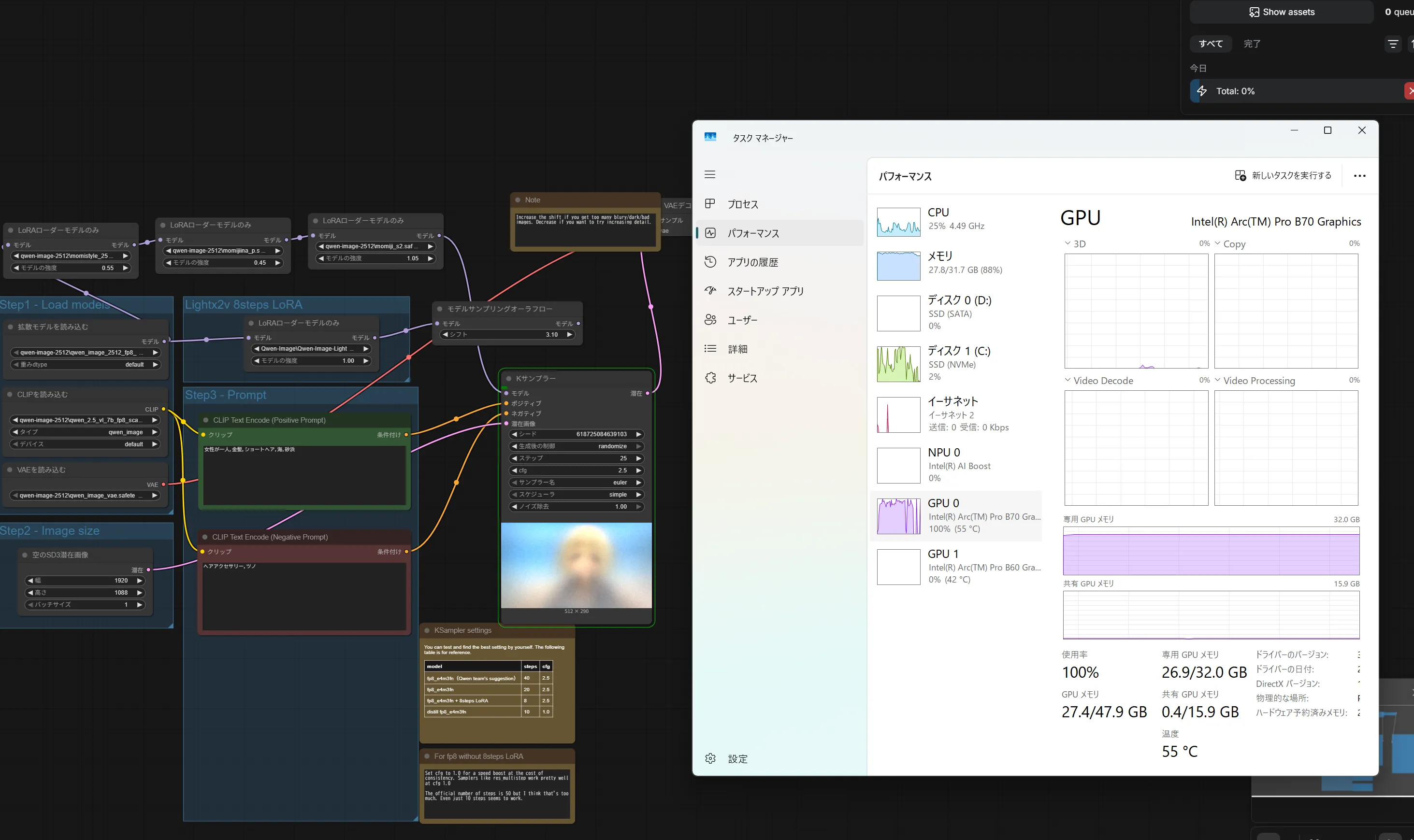
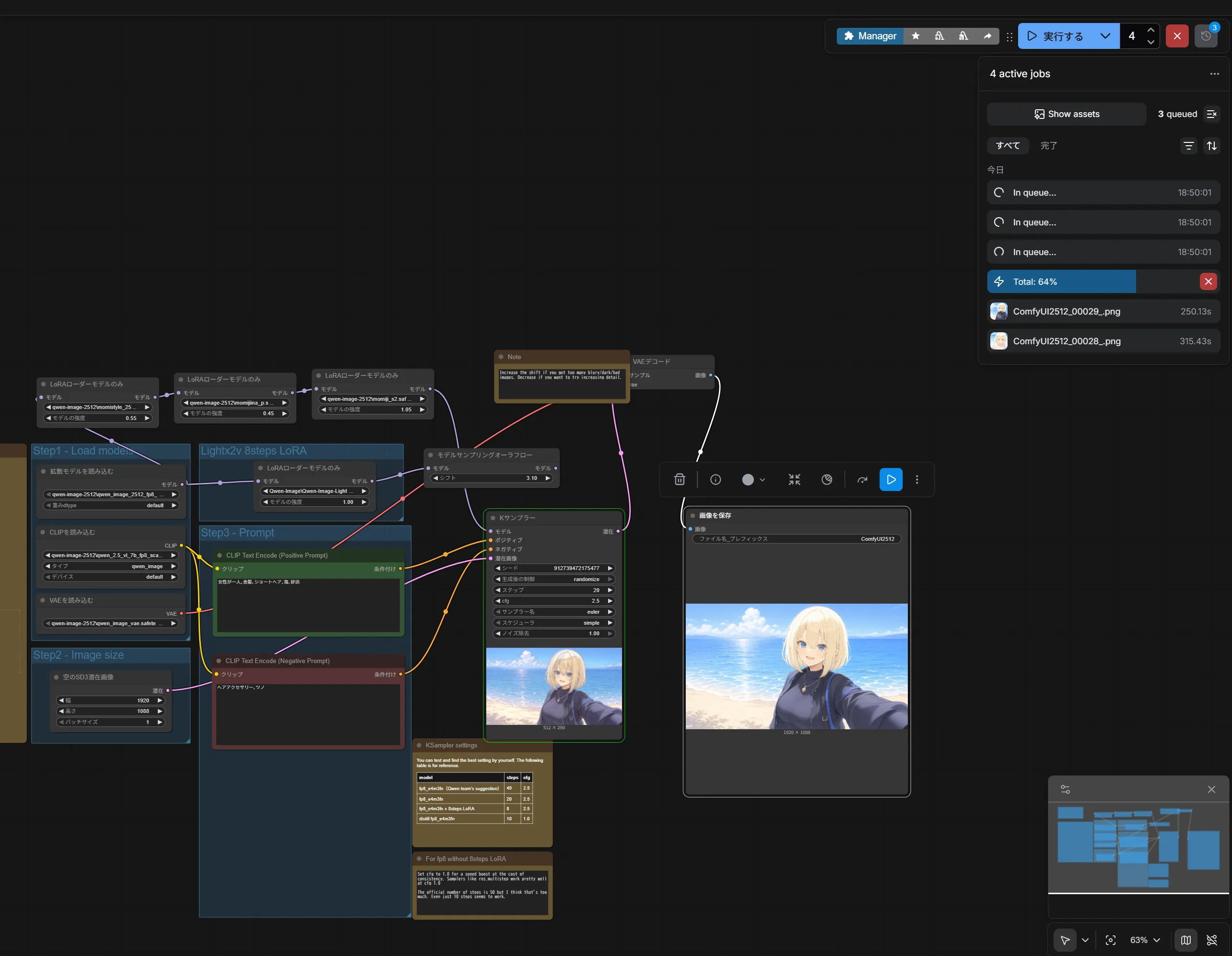






 うまくいくときもありますが増えると崩壊しますね
うまくいくときもありますが増えると崩壊しますね






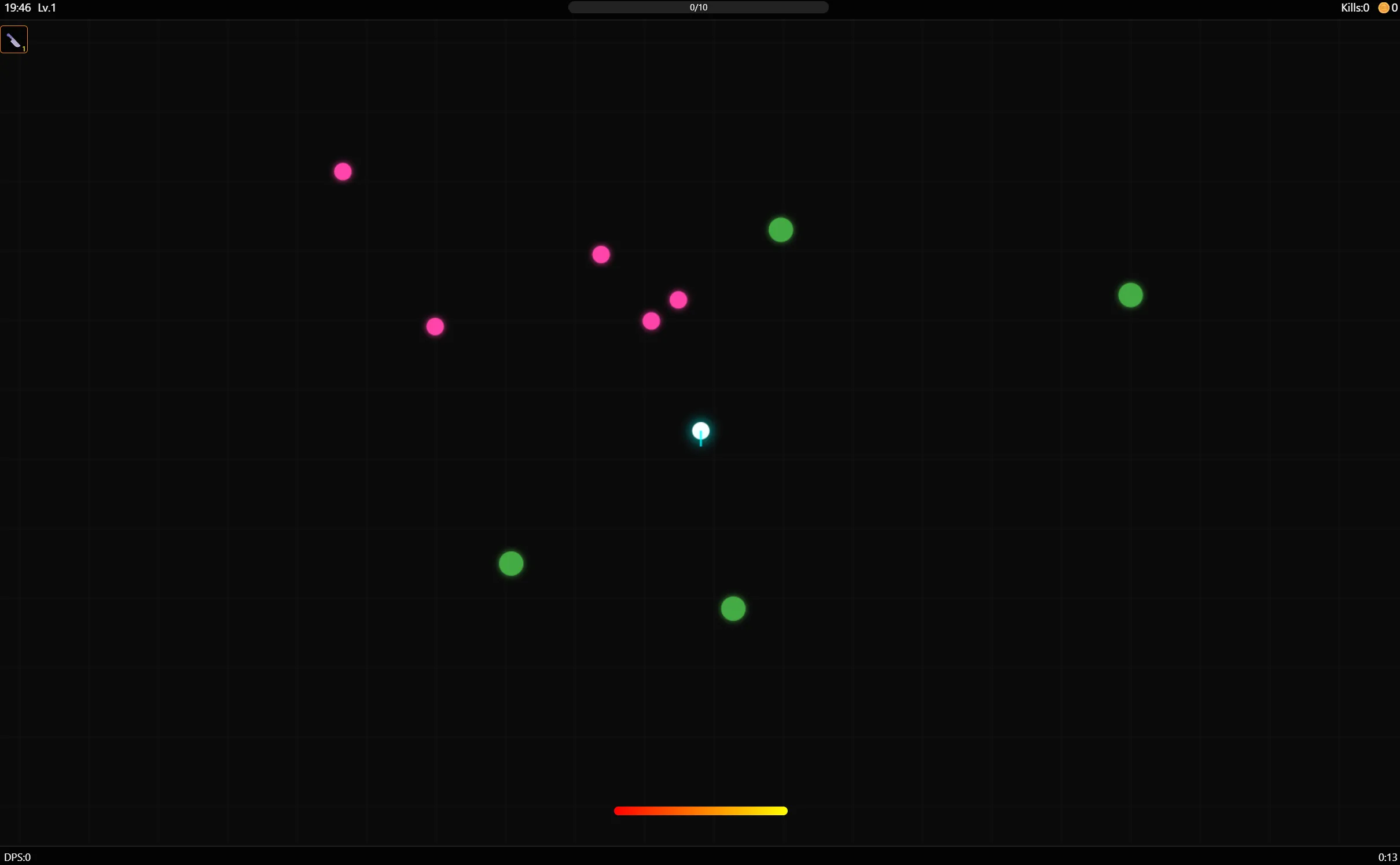 ヴァンパイアサバイバー風ゲームをつくらせてますがわからないレベルです。
ヴァンパイアサバイバー風ゲームをつくらせてますがわからないレベルです。