Intel Arc Pro B60の環境を調整したから70bから20bまでテストするぞ

Intel Arc Pro b60の再計測です。
買う方がいるならまぁ参考に・・・
Intel Arc Pro B60 24GBの在庫はどこにいったんですかねこれ
llama-3.3-70bを計測する
短い質問
まず少し古いですがいいのがなかったのでこの70bモデルです。
まず短い質問で9.79token/sでした。

500文字程度の生成はどうか?
8.47token/sです。
文章をつくるだけなら問題ないくらいの速度ですかね
かなり長いコードを生成させる
6.41token/sと前よりもはね?
HyperNova-60bを計測する
最近でたばっかりのgpt-oss 120b関連のモデルらしい?
短い質問
見てくださいこの速度
62token/sです。
500文字程度の生成はどうか?
かなり長いコードを生成させる
44token/sとかなりいい速度がでてますがこのモデルのコード生成は微妙でしたね・・・
※このモデルはまだ微妙
日本語も微妙です5000文字で物語を指定したら日本語と英語がまざりました。
Qwen3 Coder 30b a3bを計測する
短い質問
30bのa3bなら85token/sもでます。

かなり長いコードを生成させる
コードモデルなので500文字はカットしてます。
36token/sです。
コンテキスト長を20万トークンにしてみる
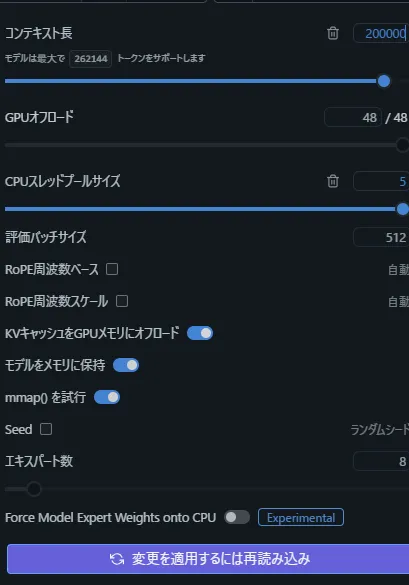
さすが20万トークンですね
40GB近くロードされます。(分割ロードなので)
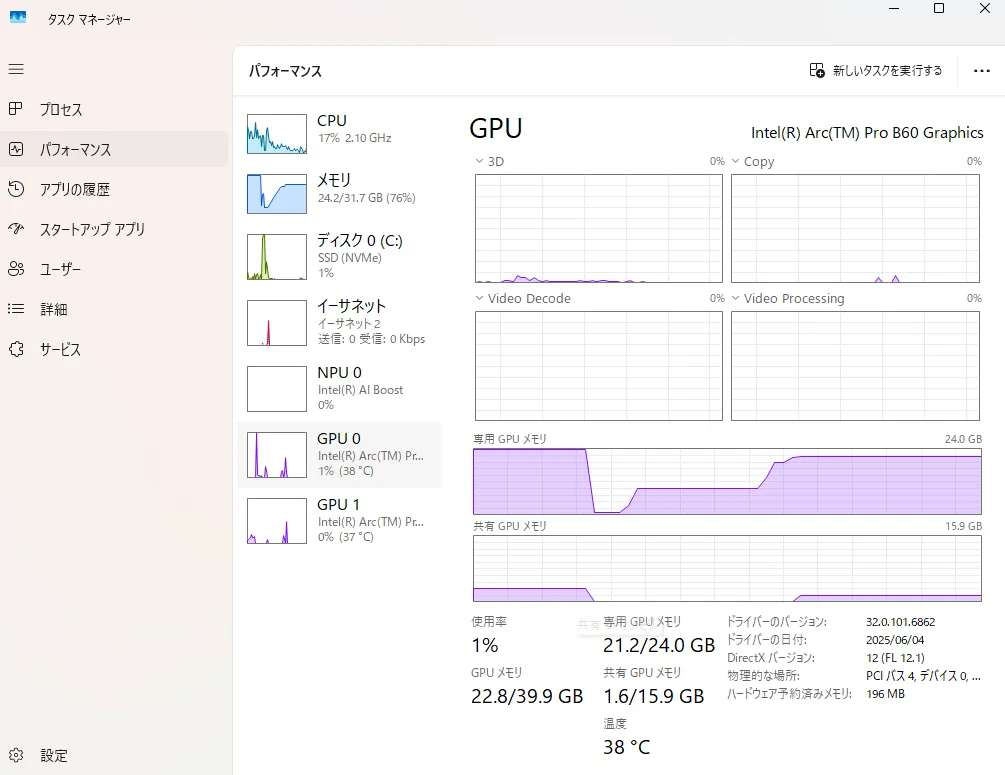
1回目の速度は問題ないですが使えて5万トークンくらいかもしれないですね・・・
gpt-oss-20bを計測する
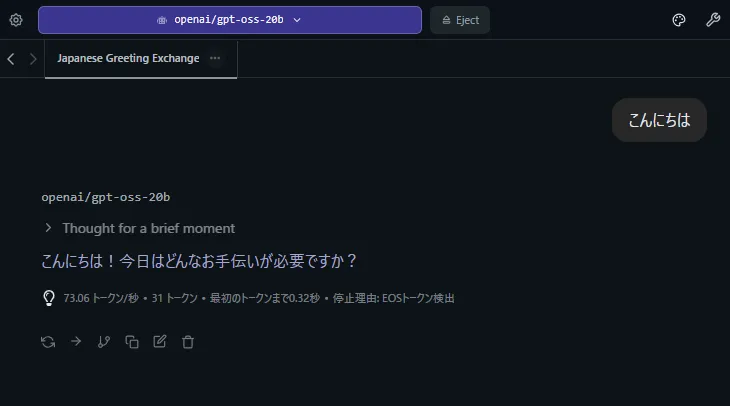
短い質問
73token/sです。
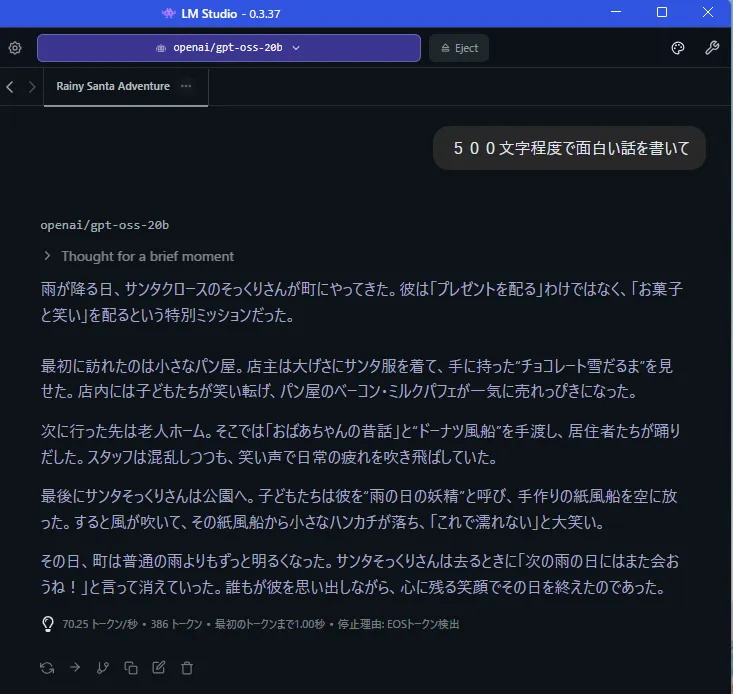
500文字程度の生成はどうか?
70token/sと悪くないですね。
最後に
いかがでしょうか48GBで24万ならわりとありなんじゃないかと思える速度だったのではないかと思いますがRTX5090とどうしても比べてしまって遅く感じてしまいます。
それにまだ最適化がすんでいないのでgpt-oss-20bも最適化によっては90token/sは出る気がするのでIntelさん早くお願いします。
llama.cppなら現状でも+20%くらいでたはずなのとRyzen AI Max+ 395 128gbですらgpt-oss-20bで60くらいでるらしいので1.5倍は帯域的にでるだろうという計算です。
Ryzen AI Max+ 395 128gbもMSIから搭載PCがでるらしいので日本で発売されるようなら比較してみたいです。