Ubuntu25でllm-scalerのvllmもテストする
· 約4分

WSLで動かないですしUbuntu 24だとGPU2枚だとエラーが出て使えなかったので公式推奨のサポート期限切れのUbuntu 25.04をインストールしてみました。
とりあえず最初にもう言っておきますがさすが推奨バージョンです。
マニュアル通り基本動きます。
あとWSLと内容が重複してます。

準備
ドライバーインストール
公式を一応みてください
dgpu-docs-intel
sudo apt-get update
sudo apt-get install -y software-properties-common
sudo add-apt-repository -y ppa:kobuk-team/intel-graphics
sudo apt-get install -y libze-intel-gpu1 libze1 intel-metrics-discovery intel-opencl-icd clinfo intel-gsc
sudo apt-get install -y intel-media-va-driver-non-free libmfx-gen1 libvpl2 libvpl-tools libva-glx2 va-driver-all vainfo
sudo apt-get install -y libze-dev intel-ocloc
sudo apt-get install -y libze-intel-gpu-raytracing
base-toolkitをインストール
公式を見てください
base-toolkit
Ubuntu25も更新しないとパッケージは見つかりません。
公開鍵の取得
wget -O- https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB \
| gpg --dearmor | sudo tee /usr/share/keyrings/oneapi-archive-keyring.gpg > /dev/null
リポジトリの追加
echo "deb [signed-by=/usr/share/keyrings/oneapi-archive-keyring.gpg] https://apt.repos.intel.com/oneapi all main" \
| sudo tee /etc/apt/sources.list.d/oneAPI.list
インストール
終わったらrebootかけてください
sudo apt update
sudo apt install intel-oneapi-base-toolkit
GPUの認識確認
export LD_LIBRARY_PATH=""
source /opt/intel/oneapi/setvars.sh --force
sycl-ls
llm-scalerのvllmをdockerでインストール
現在はlatestも1.3なので確認してください。
一覧
sudo docker run -it --name my-vllm \
--privileged \
--net=host \
--device=/dev/dri \
--name=lsv-container \
-v /home/intel/LLM:/llm/models/ \
-e no_proxy=localhost,127.0.0.1 \
-e http_proxy=$http_proxy \
-e https_proxy=$https_proxy \
--shm-size="16g" \
--entrypoint /bin/bash \
intel/llm-scaler-vllm:1.3
モデルのダウンロード
最初にモデルダウンロードしたほうが絶対いいですね・・・
huggingface-cli download deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --local-dir DeepSeek-R1-Distill-Qwen-7B
gpt-oss-20b
huggingface-cli download openai/gpt-oss-20b --local-dir /llm/models/gpt-oss-20b
実行する
gpt-ossはbfloat16で大丈夫みたいですね
float16でやったり前はしてたので今回のバージョンはしっかりエラーでたのでわかりました。
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 \
VLLM_WORKER_MULTIPROC_METHOD=spawn \
vllm serve \
--model /llm/models/gpt-oss-20b \
--served-model-name gpt-oss-20b \
--quantization mxfp4 \
--dtype bfloat16 \
--host 0.0.0.0 \
--port 8000 \
--trust-remote-code \
--gpu-memory-util 0.9 \
--max-model-len 8192
-tp 2
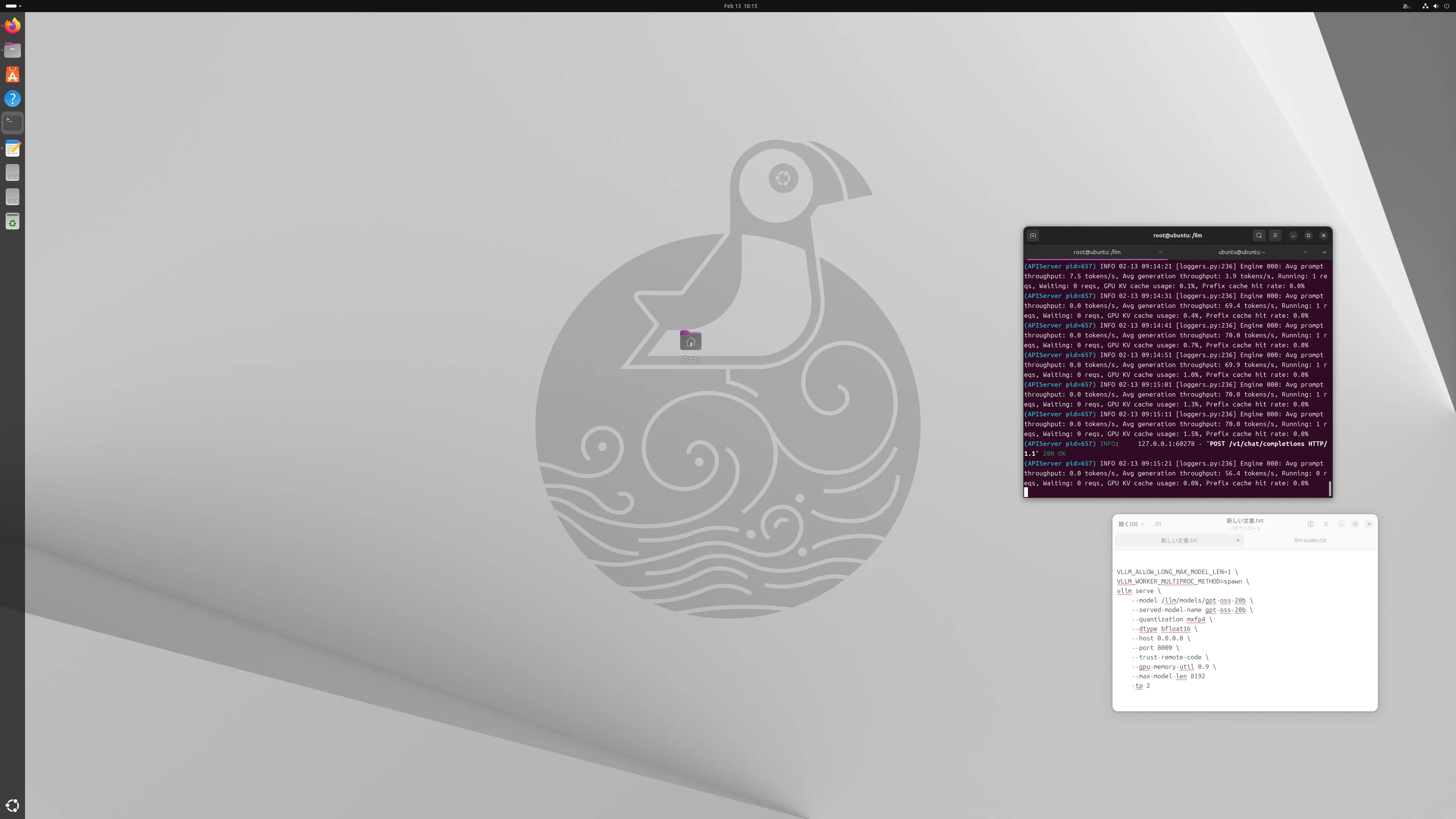
速度はどれくらいでるのか
1枚も2枚も速度差はなかったです。
最大70token/sなのでLM Studio以下ですね。
今,LM Studioなら80token/s以上一応でてますので・・・・
途中でモニターを4Kに変えたので見ずらいですけど編集めんどくさいのでズームしてください(必要なら)
一応、以下を実行してます。
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-oss-20b",
"messages": [
{"role": "user", "content": "Hello! How are you?"}
],
"max_tokens": 4096
}'
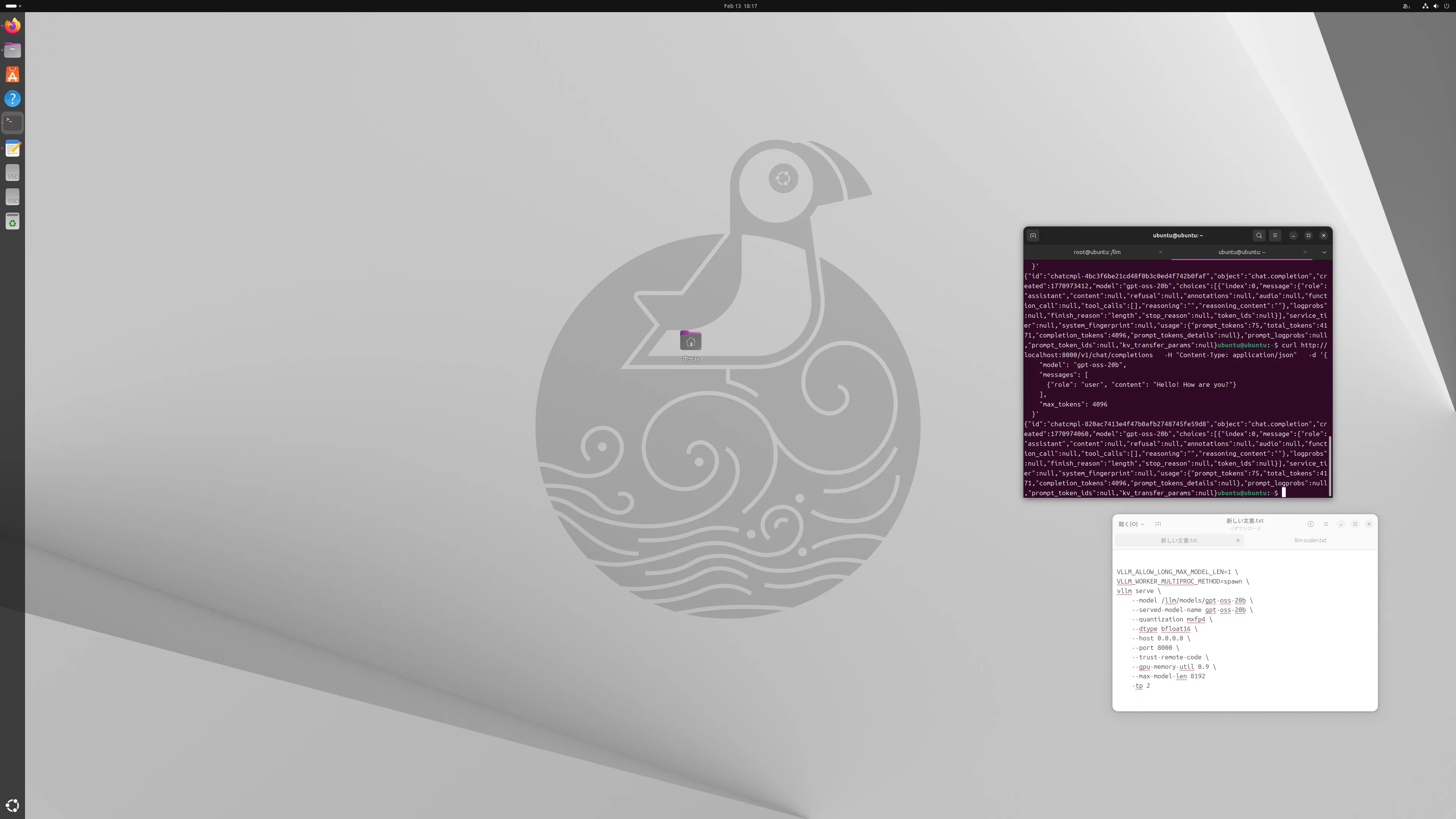
ArcシリーズはやっぱりWindowsでのほうが速そうですね。
llm-scalerのomniももしかしたらテストするかもしれないです。
Wan2.2をGPU2枚で実行できるらしい?ので