using System;
using System.Linq;
using System.Text;
using System.Text.RegularExpressions;
using System.Threading;
using System.Threading.Tasks;
using LLama;
using LLama.Common;
using LLama.Sampling;
using LocalTranslatorWPF.Models;
namespace LocalTranslatorWPF.Services
{
public class TranslationService : IDisposable
{
private LLamaWeights _model;
private LLamaContext _context;
private bool _isInitialized;
public async Task<bool> InitializeModel(ModelInfo modelInfo, bool useGPU, Action<string> logCallback = null)
{
try
{
Cleanup();
logCallback?.Invoke($"モデルを読み込んでいます: {modelInfo.Name}...");
var parameters = new ModelParams(modelInfo.Path)
{
ContextSize = 2048,
GpuLayerCount = useGPU ? 35 : 0,
UseMemorymap = true,
UseMemoryLock = false
};
_model = await Task.Run(() => LLamaWeights.LoadFromFile(parameters));
_context = _model.CreateContext(parameters);
_isInitialized = true;
logCallback?.Invoke($"モデルの読み込みが完了しました。GPU使用: {useGPU}");
return true;
}
catch (Exception ex)
{
logCallback?.Invoke($"エラー: {ex.Message}");
_isInitialized = false;
return false;
}
}
public async Task<string> TranslateAsync(TranslationRequest request, Action<string> progressCallback = null, CancellationToken cancellationToken = default)
{
if (!_isInitialized)
throw new InvalidOperationException("モデルが初期化されていません。");
// 同じ言語かどうかをチェック
var detectedLanguage = DetectLanguage(request.SourceText);
var targetLanguage = request.TargetLanguage;
// 日本語→日本語、英語→英語の場合はスキップ
if ((detectedLanguage == "Japanese" && targetLanguage == "Japanese") ||
(detectedLanguage == "English" && targetLanguage == "English"))
{
var message = detectedLanguage == "Japanese"
? "日本語から日本語への翻訳のため、翻訳しませんでした。"
: "英語から英語への翻訳のため、翻訳しませんでした。";
progressCallback?.Invoke(message);
return message;
}
var prompt = CreateTranslationPrompt(request);
progressCallback?.Invoke("翻訳中...");
var inferenceParams = new InferenceParams
{
MaxTokens = 2048,
SamplingPipeline = new DefaultSamplingPipeline
{
Temperature = 0.6f,
TopP = 0.95f,
TopK = 20,
MinP = 0
},
AntiPrompts = new[] {
"<<<END>>>",
"\n\n\n",
"###",
"\n---"
}
};
var executor = new InteractiveExecutor(_context);
var result = new StringBuilder();
await foreach (var text in executor.InferAsync(prompt, inferenceParams, cancellationToken))
{
result.Append(text);
var currentText = result.ToString();
// 終了デリミタを検出
if (currentText.Contains("<<<END>>>"))
{
break;
}
// 進捗表示用に翻訳結果を抽出
var extractedTranslation = ExtractTranslationFromDelimiters(currentText);
if (!string.IsNullOrEmpty(extractedTranslation))
{
// 元のテキストと同じ場合は表示しない(翻訳失敗の可能性)
if (!IsSameContent(extractedTranslation, request.SourceText))
{
progressCallback?.Invoke(extractedTranslation);
}
}
}
// 最終的な翻訳結果を抽出
var finalResult = ExtractTranslationFromDelimiters(result.ToString());
if (string.IsNullOrEmpty(finalResult))
{
// デリミタ抽出失敗時はテキストクリーニングにフォールバック
finalResult = CleanTranslationResult(result.ToString(), request.SourceLanguage);
}
// 元のテキストと同じ場合はエラーメッセージ
if (IsSameContent(finalResult, request.SourceText))
{
var errorMessage = "翻訳に失敗しました。モデルが指示を理解できませんでした。";
progressCallback?.Invoke(errorMessage);
return errorMessage;
}
progressCallback?.Invoke(finalResult);
return finalResult.Trim();
}
private bool IsSameContent(string text1, string text2)
{
if (string.IsNullOrWhiteSpace(text1) || string.IsNullOrWhiteSpace(text2))
return false;
// 空白と句読点を除去して比較
var normalized1 = Regex.Replace(text1.ToLower(), @"[\s\p{P}]", "");
var normalized2 = Regex.Replace(text2.ToLower(), @"[\s\p{P}]", "");
// 完全一致または90%以上一致していれば同じとみなす
if (normalized1 == normalized2)
return true;
// レーベンシュタイン距離で類似度チェック
int distance = LevenshteinDistance(normalized1, normalized2);
int maxLength = Math.Max(normalized1.Length, normalized2.Length);
double similarity = 1.0 - (double)distance / maxLength;
return similarity > 0.9;
}
private int LevenshteinDistance(string s1, string s2)
{
int[,] d = new int[s1.Length + 1, s2.Length + 1];
for (int i = 0; i <= s1.Length; i++)
d[i, 0] = i;
for (int j = 0; j <= s2.Length; j++)
d[0, j] = j;
for (int j = 1; j <= s2.Length; j++)
{
for (int i = 1; i <= s1.Length; i++)
{
int cost = (s1[i - 1] == s2[j - 1]) ? 0 : 1;
d[i, j] = Math.Min(Math.Min(d[i - 1, j] + 1, d[i, j - 1] + 1), d[i - 1, j - 1] + cost);
}
}
return d[s1.Length, s2.Length];
}
private string ExtractTranslationFromDelimiters(string text)
{
if (string.IsNullOrWhiteSpace(text))
return string.Empty;
// <<<START>>> と <<<END>>> の間を抽出
var match = Regex.Match(text, @"<<<START>>>(.*?)(?:<<<END>>>|$)", RegexOptions.Singleline);
if (match.Success && match.Groups.Count > 1)
{
return match.Groups[1].Value.Trim();
}
return string.Empty;
}
private string DetectLanguage(string text)
{
if (string.IsNullOrWhiteSpace(text))
return "Unknown";
// 日本語文字(ひらがな、カタカナ、漢字)の割合をチェック
int japaneseCharCount = 0;
int totalChars = 0;
foreach (char c in text)
{
if (char.IsWhiteSpace(c) || char.IsPunctuation(c))
continue;
totalChars++;
if ((c >= 0x3040 && c <= 0x309F) || // ひらがな
(c >= 0x30A0 && c <= 0x30FF) || // カタカナ
(c >= 0x4E00 && c <= 0x9FAF)) // 漢字
{
japaneseCharCount++;
}
}
if (totalChars == 0)
return "Unknown";
double japaneseRatio = (double)japaneseCharCount / totalChars;
return japaneseRatio >= 0.3 ? "Japanese" : "English";
}
private string CleanTranslationResult(string result, string sourceLanguage)
{
// デリミタを削除
result = result.Replace("<<<START>>>", "").Replace("<<<END>>>", "");
// 改行が2つ以上続く場合、最初の部分だけを取得
var parts = result.Split(new[] { "\n\n" }, StringSplitOptions.RemoveEmptyEntries);
if (parts.Length > 0)
{
result = parts[0];
}
// 不要な接頭辞を削除
var prefixesToRemove = new[]
{
"英語: ",
"日本語: ",
"English: ",
"Japanese: ",
"翻訳: ",
"Translation: ",
"訳: "
};
foreach (var prefix in prefixesToRemove)
{
if (result.StartsWith(prefix, StringComparison.OrdinalIgnoreCase))
{
result = result.Substring(prefix.Length);
}
}
return result.Trim();
}
private string CreateTranslationPrompt(TranslationRequest request)
{
if (request.SourceLanguage == "Japanese")
{
// 日本語→英語(Few-shot付き)
return $@"あなたは翻訳者です。日本語を英語に翻訳してください。
例1:
日本語: こんにちは、元気ですか?
翻訳: <<<START>>>Hello, how are you?<<<END>>>
例2:
日本語: 今日は良い天気ですね。明日も晴れるそうです。
翻訳: <<<START>>>It's nice weather today.It's supposed to be sunny again tomorrow.<<<END>>>
実際のタスク:
日本語: {request.SourceText}
翻訳: <<<START>>>";
}
else
{
// 英語→日本語(Few-shot付き)
return $@"あなたは翻訳者です。英語を日本語に翻訳してください。必ず日本語で答えてください。
例1:
English: Hello, how are you?
翻訳: <<<START>>>こんにちは、元気ですか?<<<END>>>
例2:
English: It's nice weather today.It's supposed to be sunny again tomorrow.
翻訳: <<<START>>>今日は良い天気ですね。明日も晴れるそうです。<<<END>>>
実際のタスク:
English: {request.SourceText}
翻訳: <<<START>>>";
}
}
private void Cleanup()
{
_context?.Dispose();
_model?.Dispose();
_context = null;
_model = null;
_isInitialized = false;
}
public void Dispose()
{
Cleanup();
}
}
}

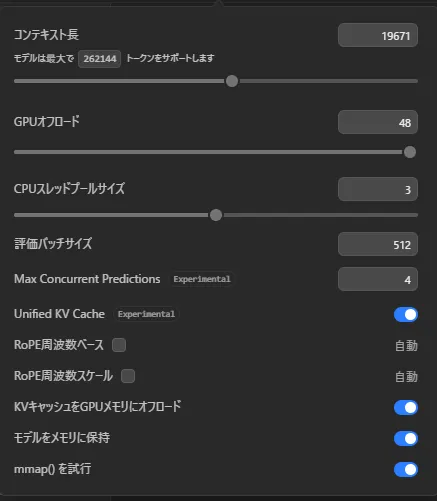
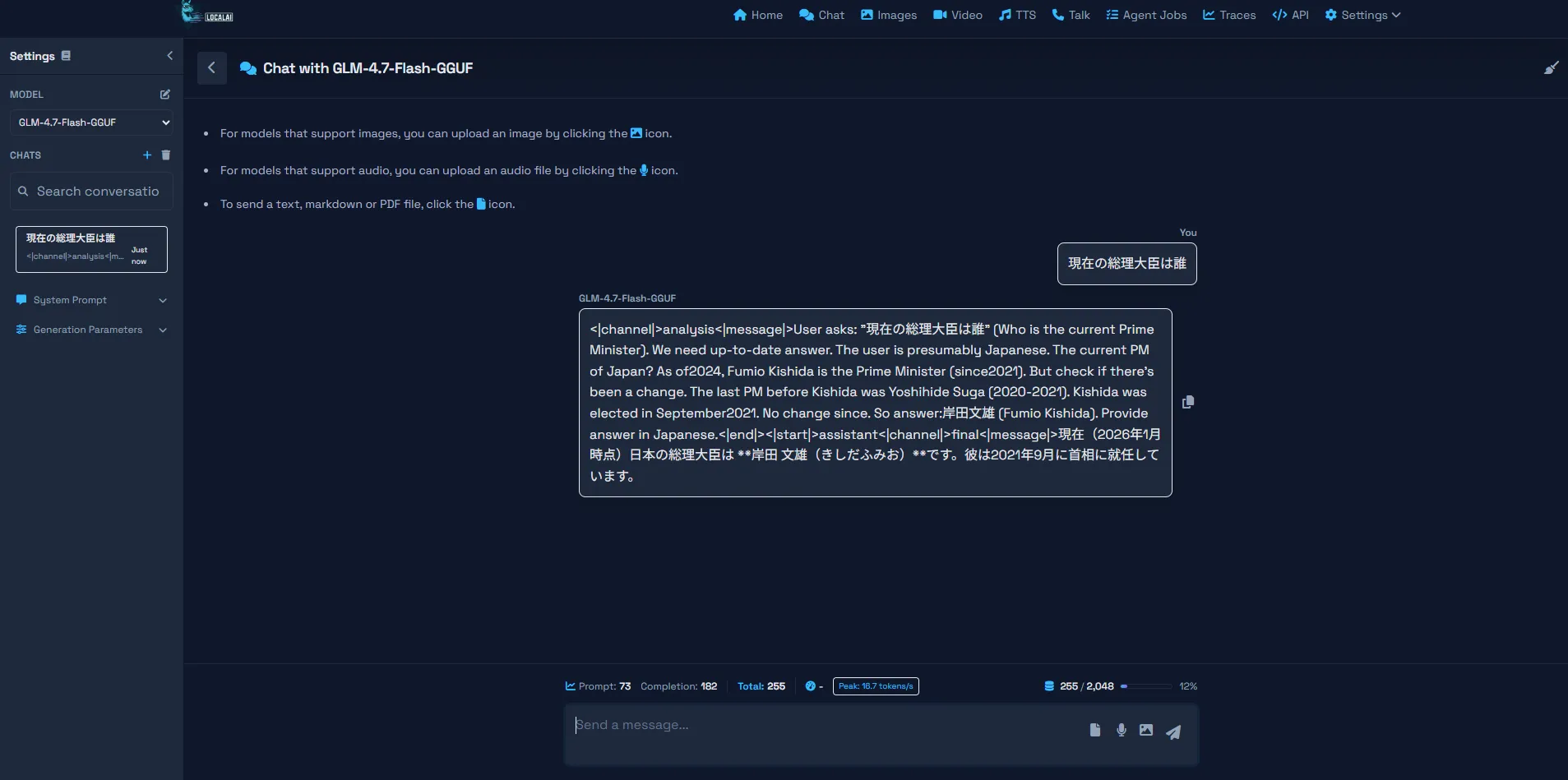
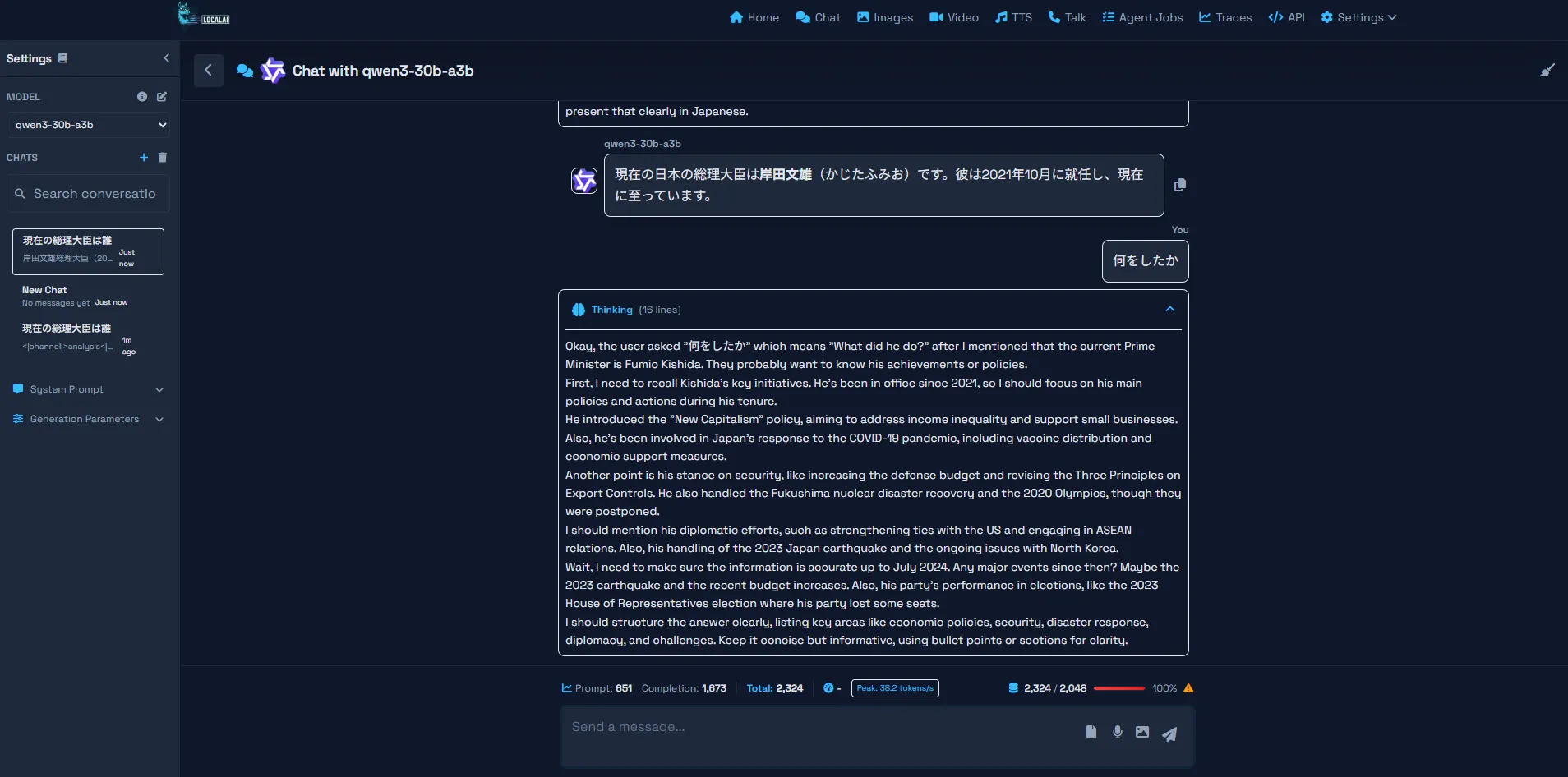
 できたのはこんな感じ
できたのはこんな感じ
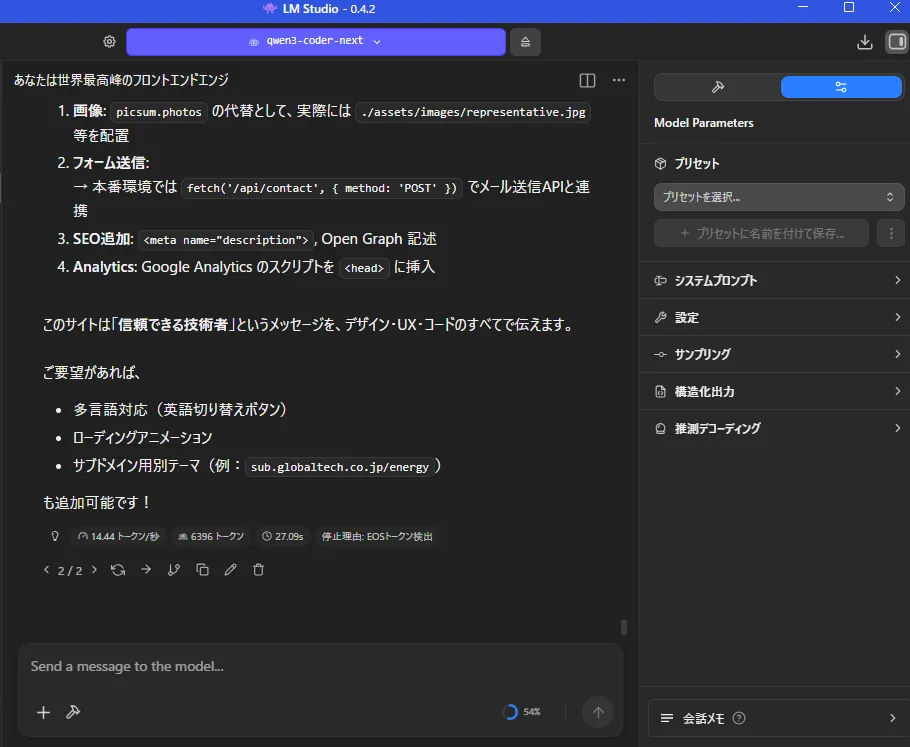
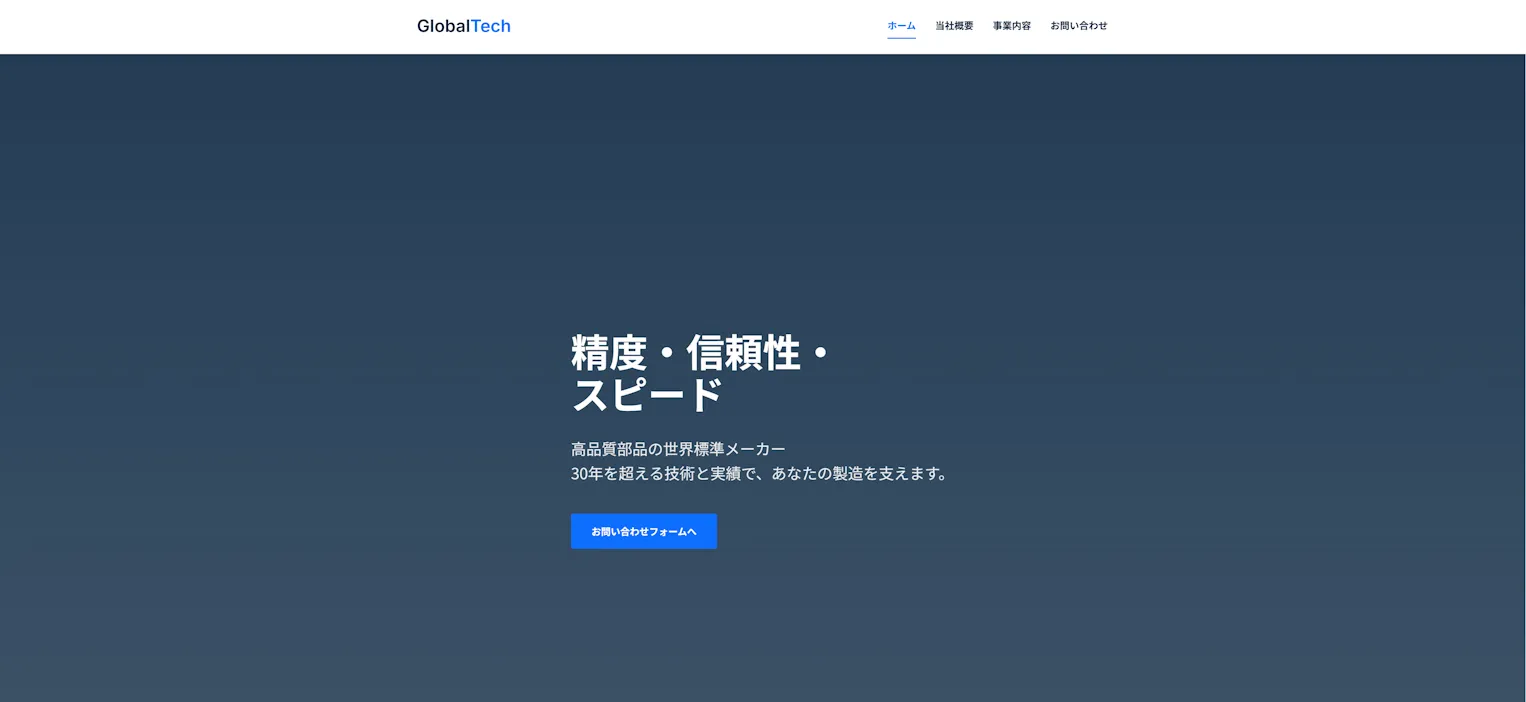
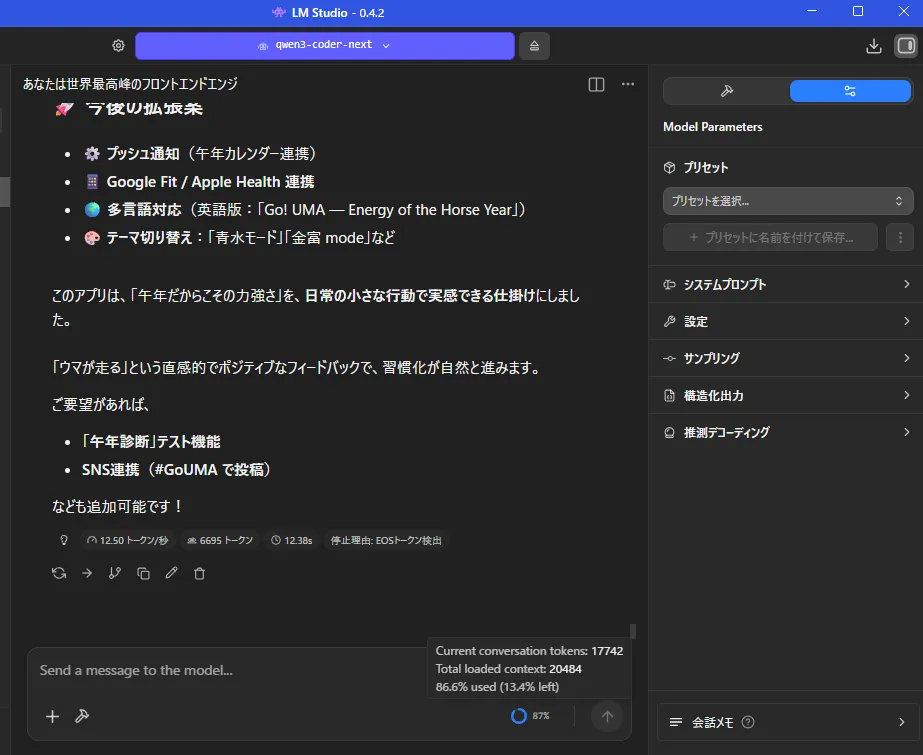
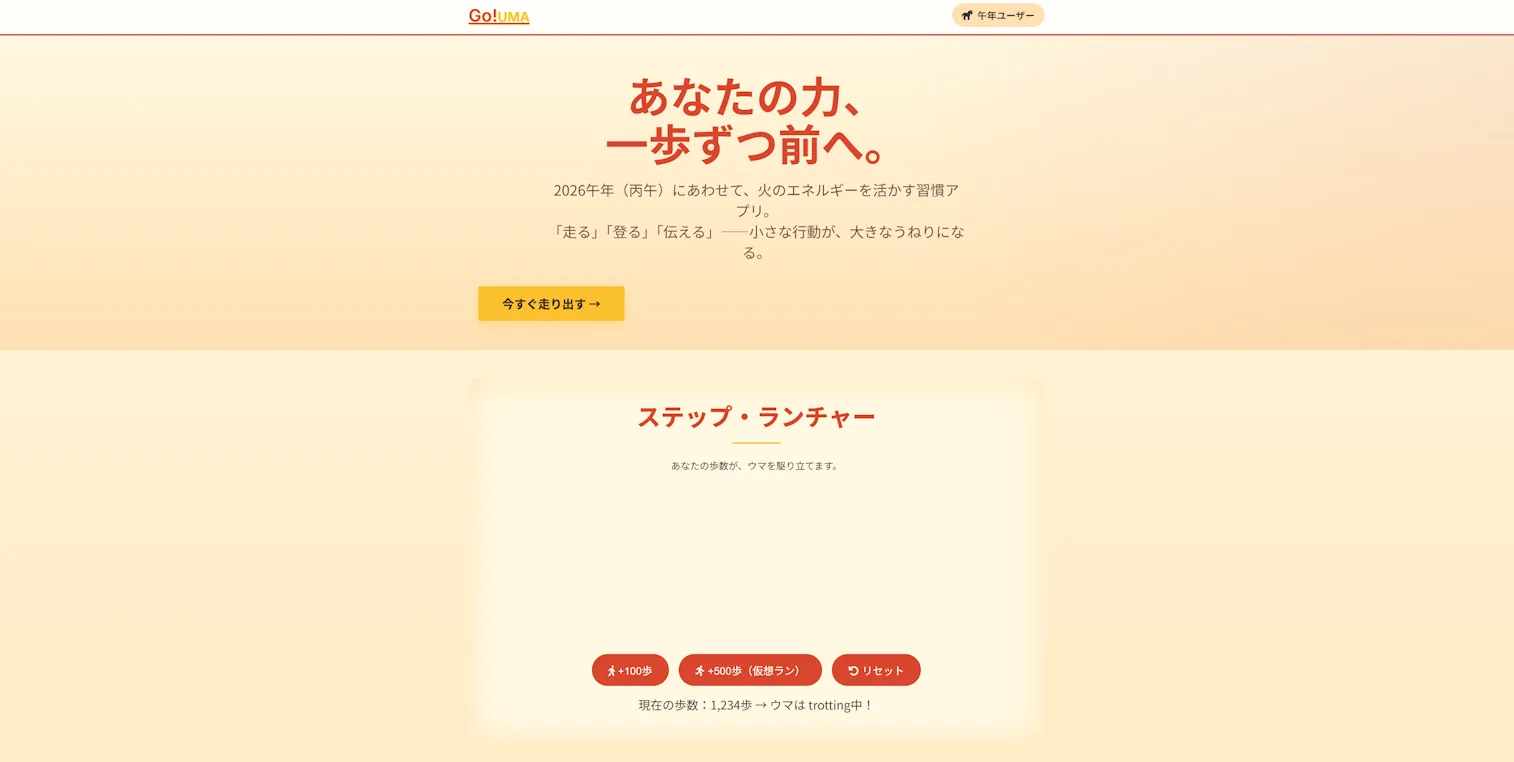
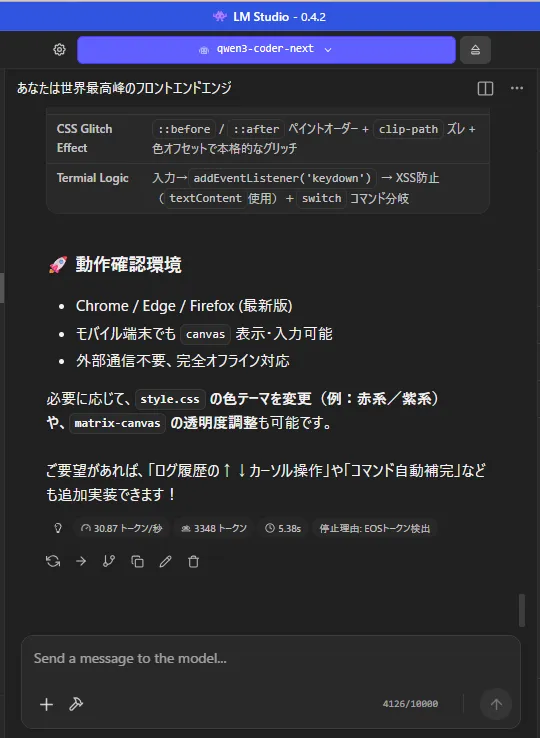
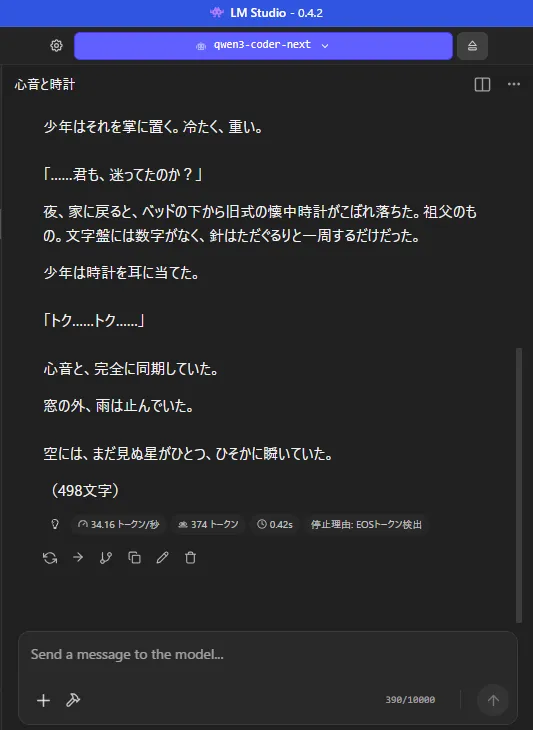
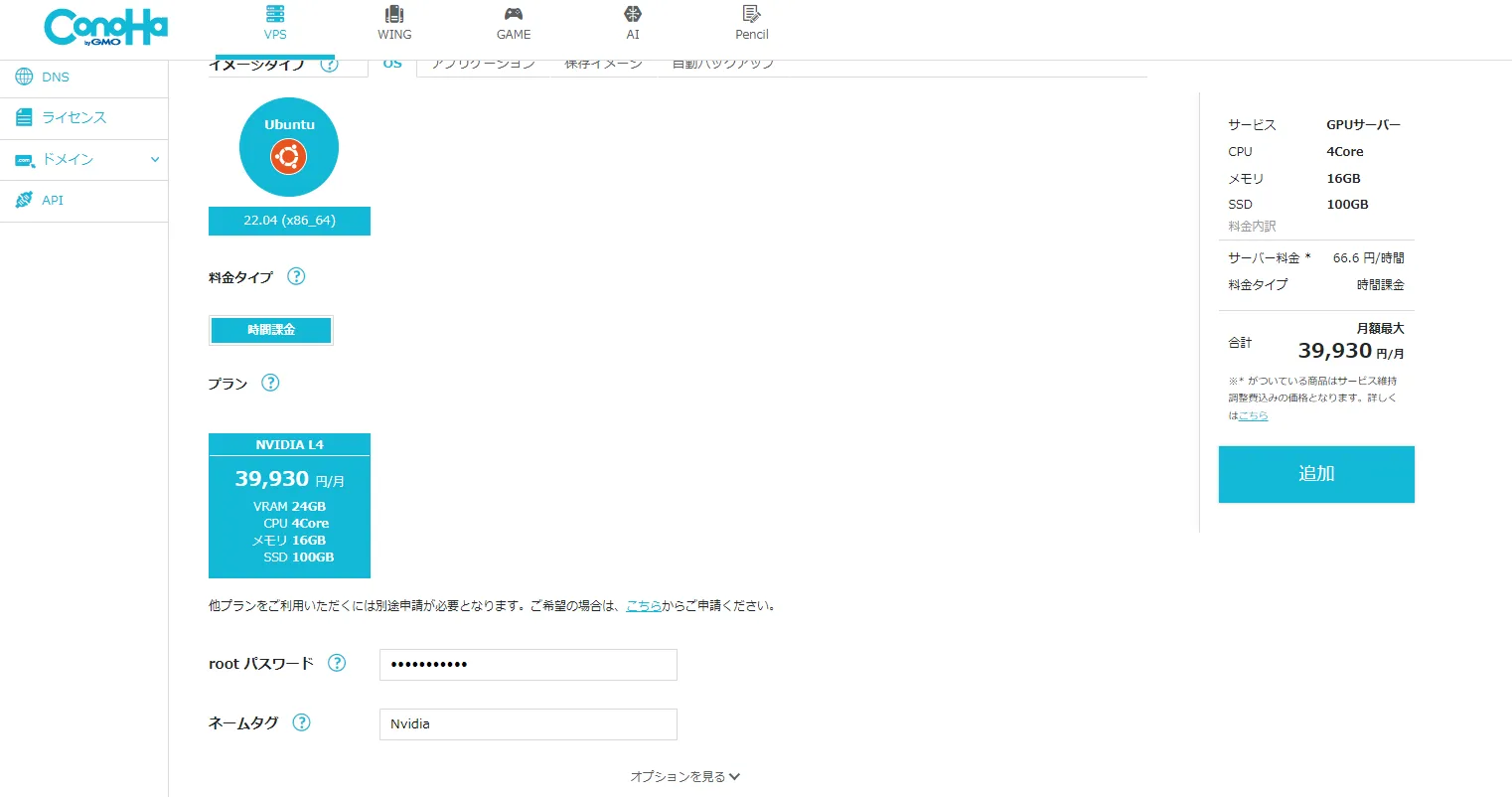


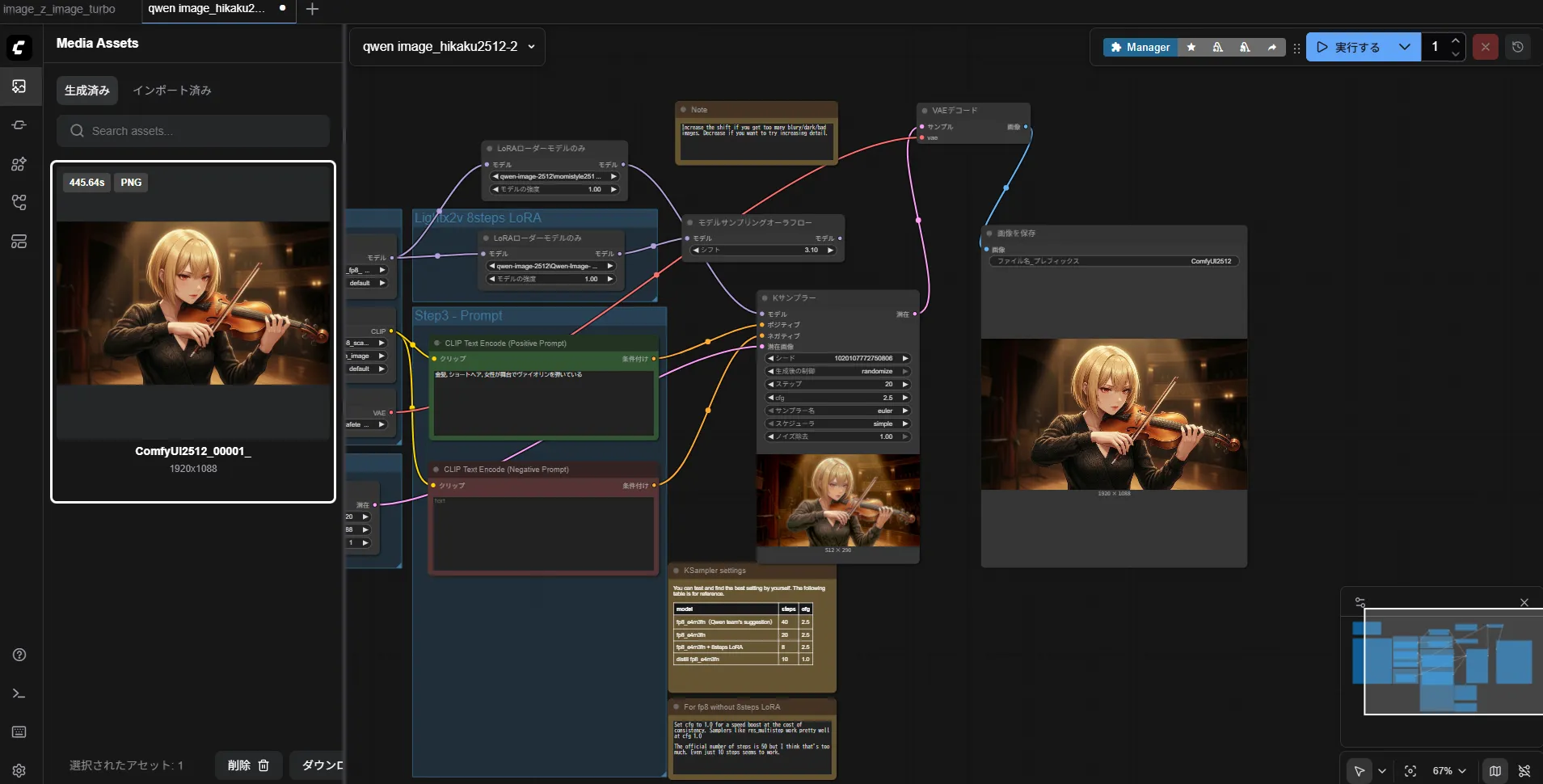
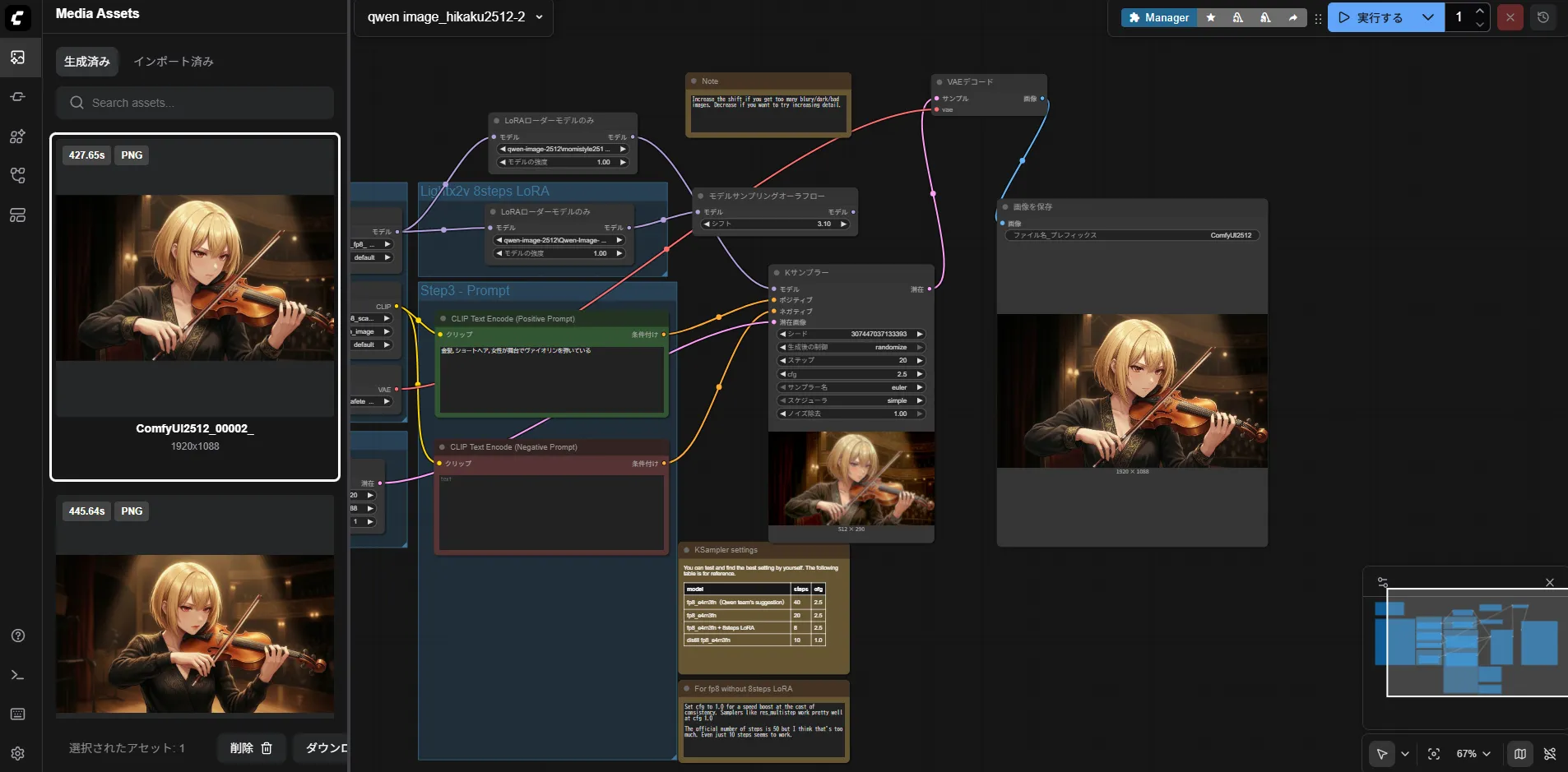
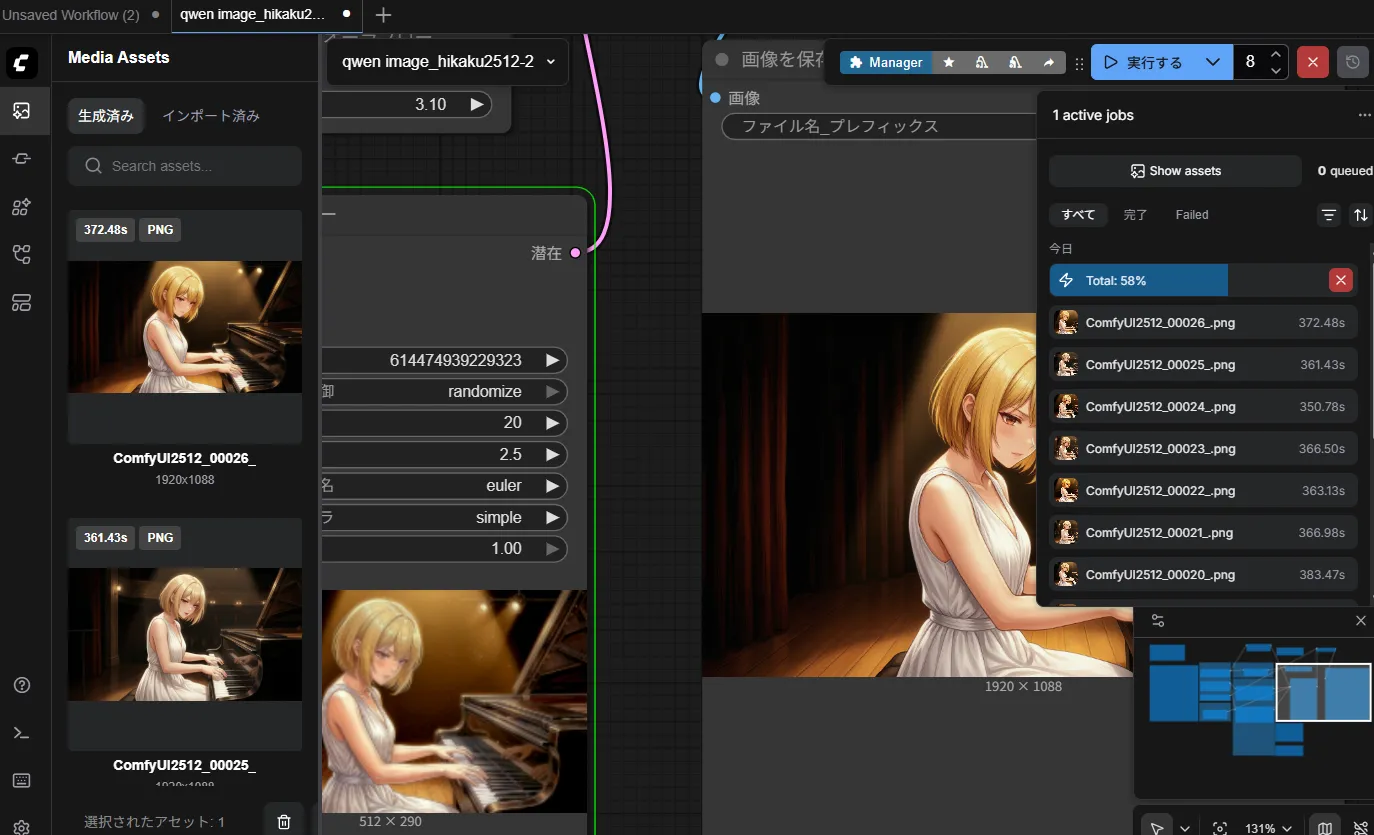 まぁ、1枚360秒はさすがに遅いのに変わりはないですけども
まぁ、1枚360秒はさすがに遅いのに変わりはないですけども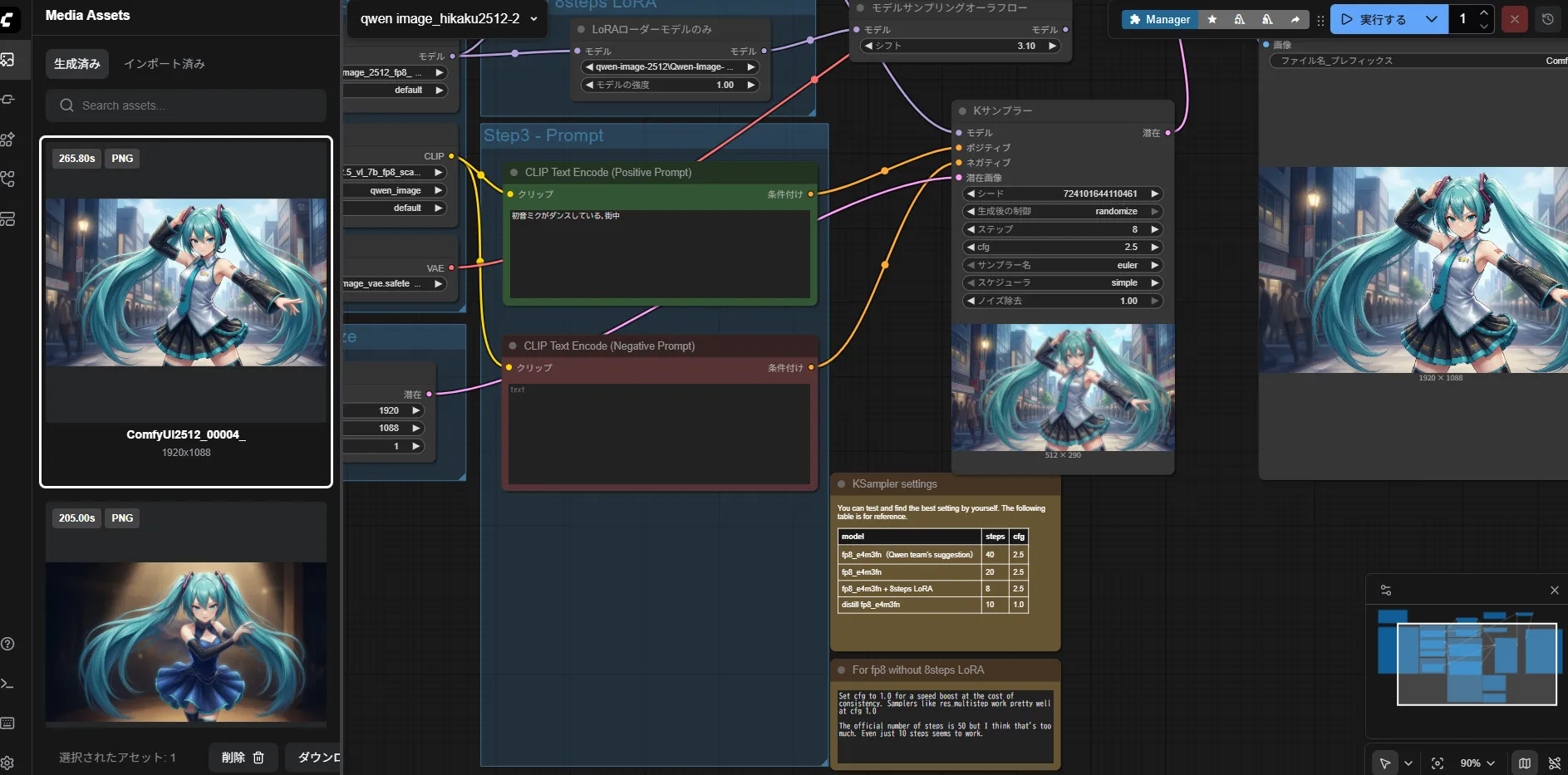

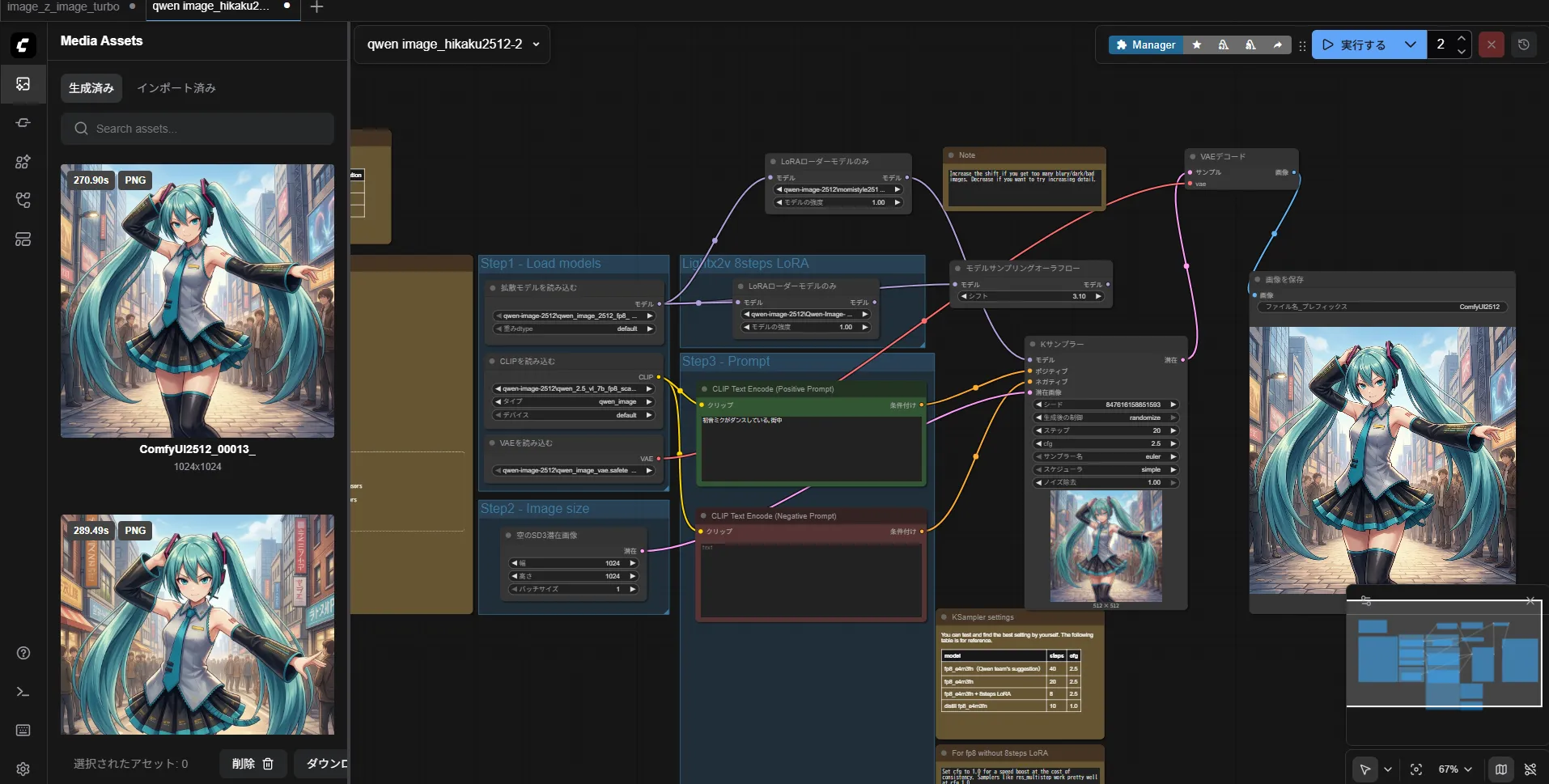

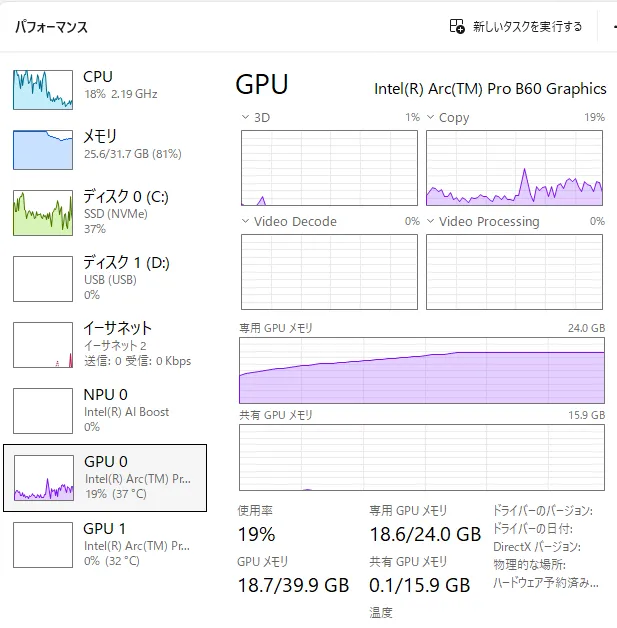



















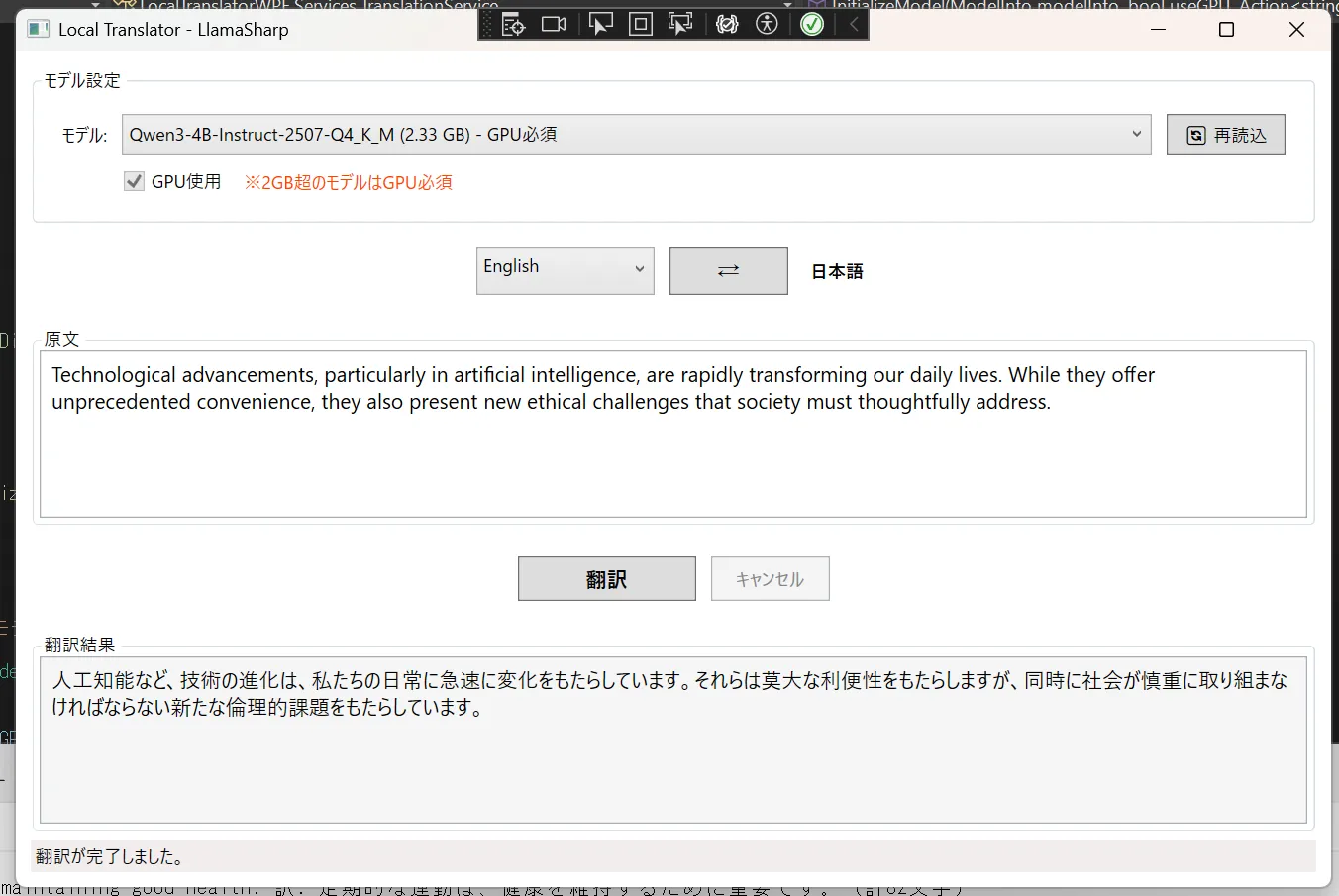
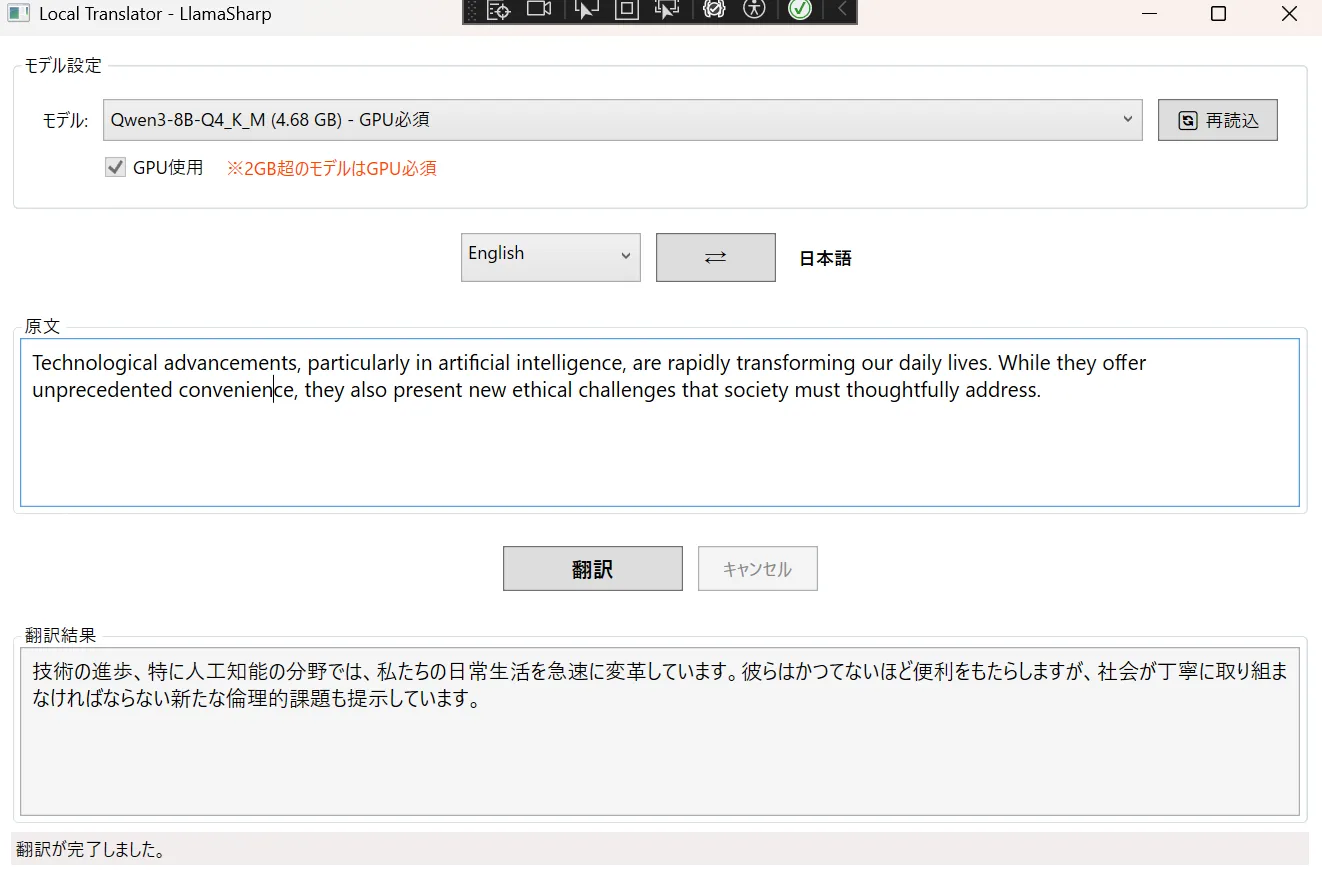
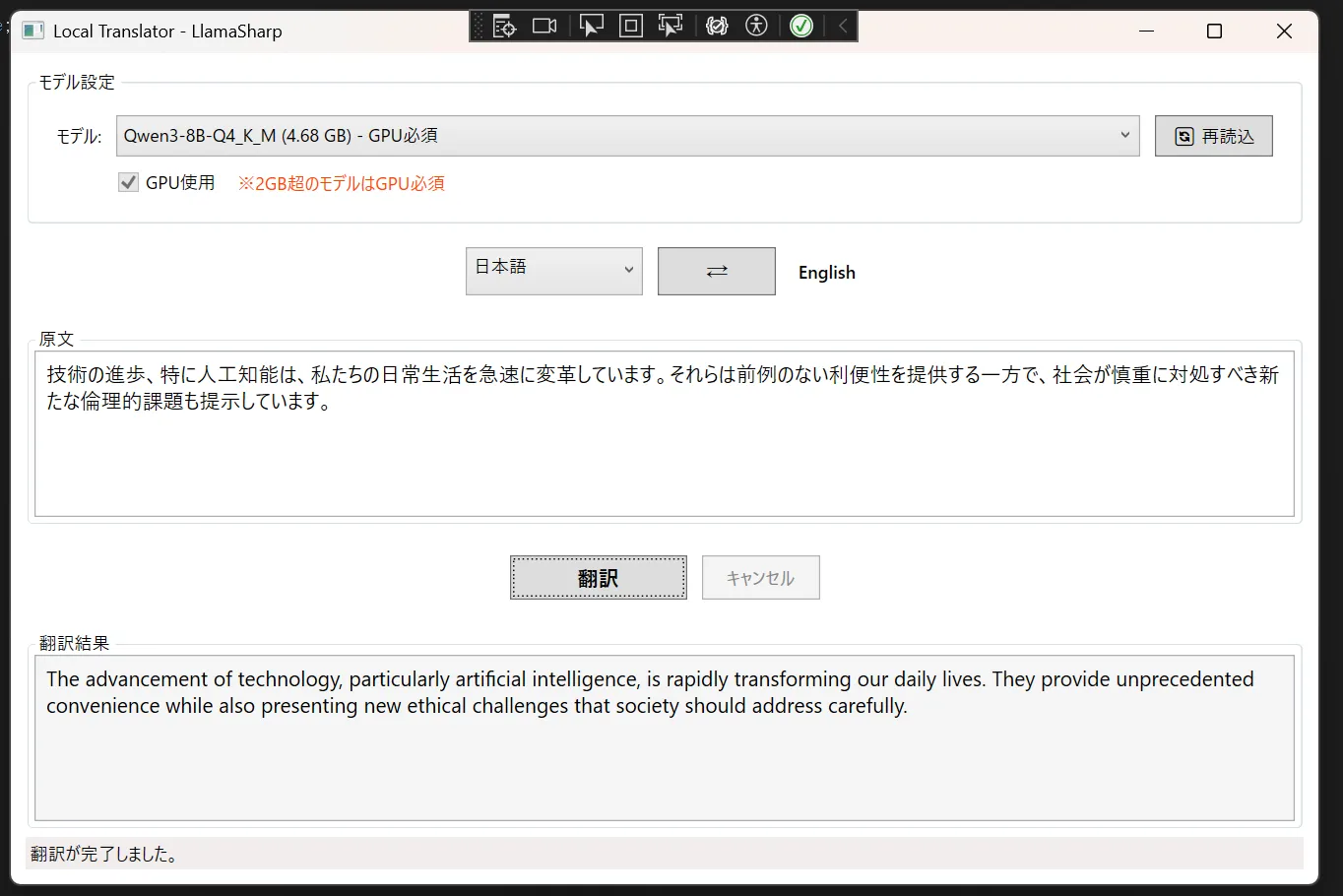
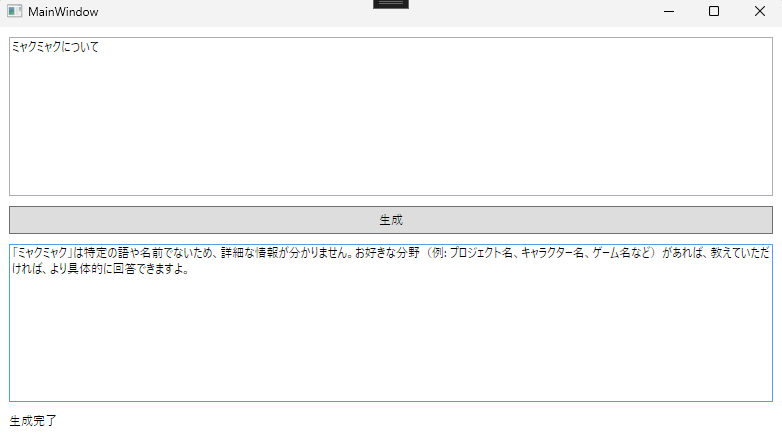 やっぱり1.7bは欲しいですねこう見ると
やっぱり1.7bは欲しいですねこう見ると

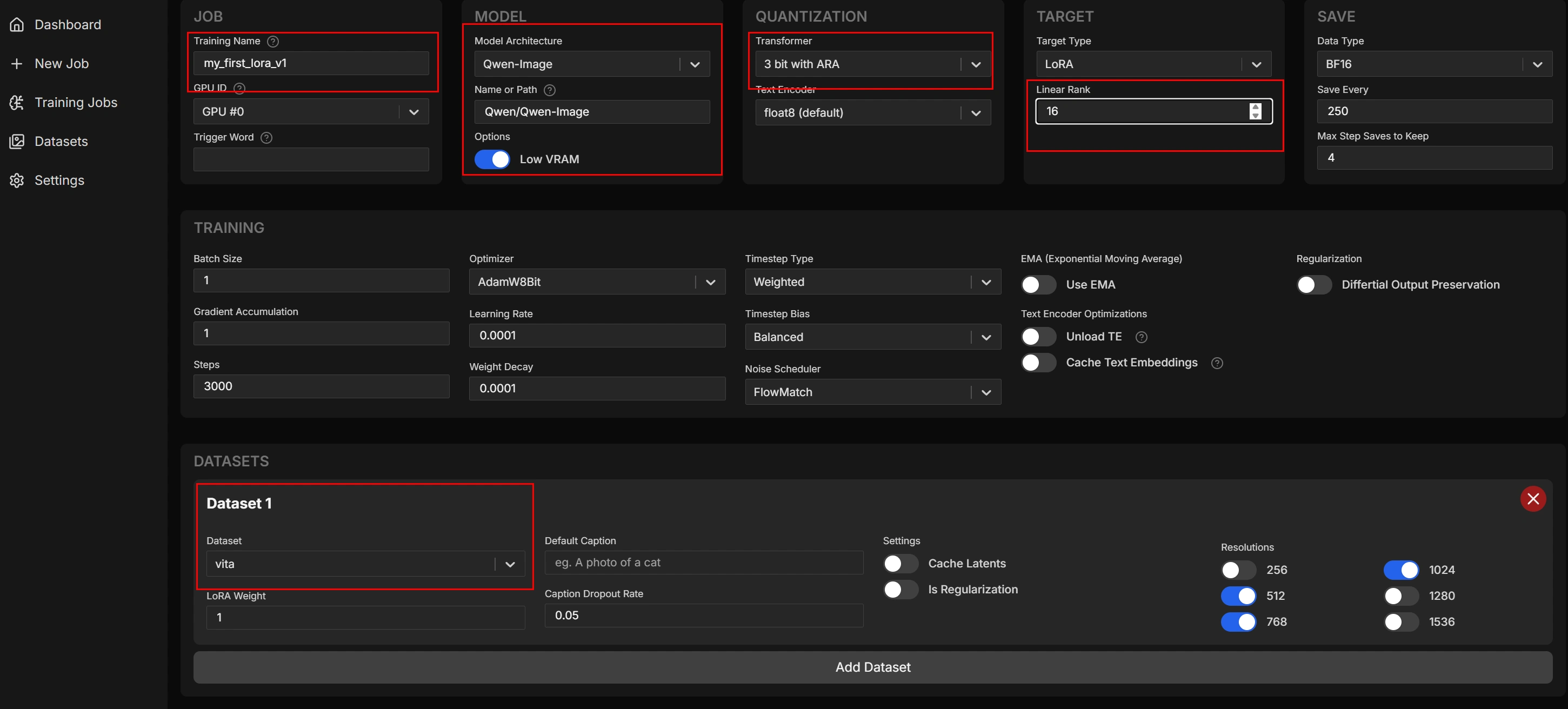
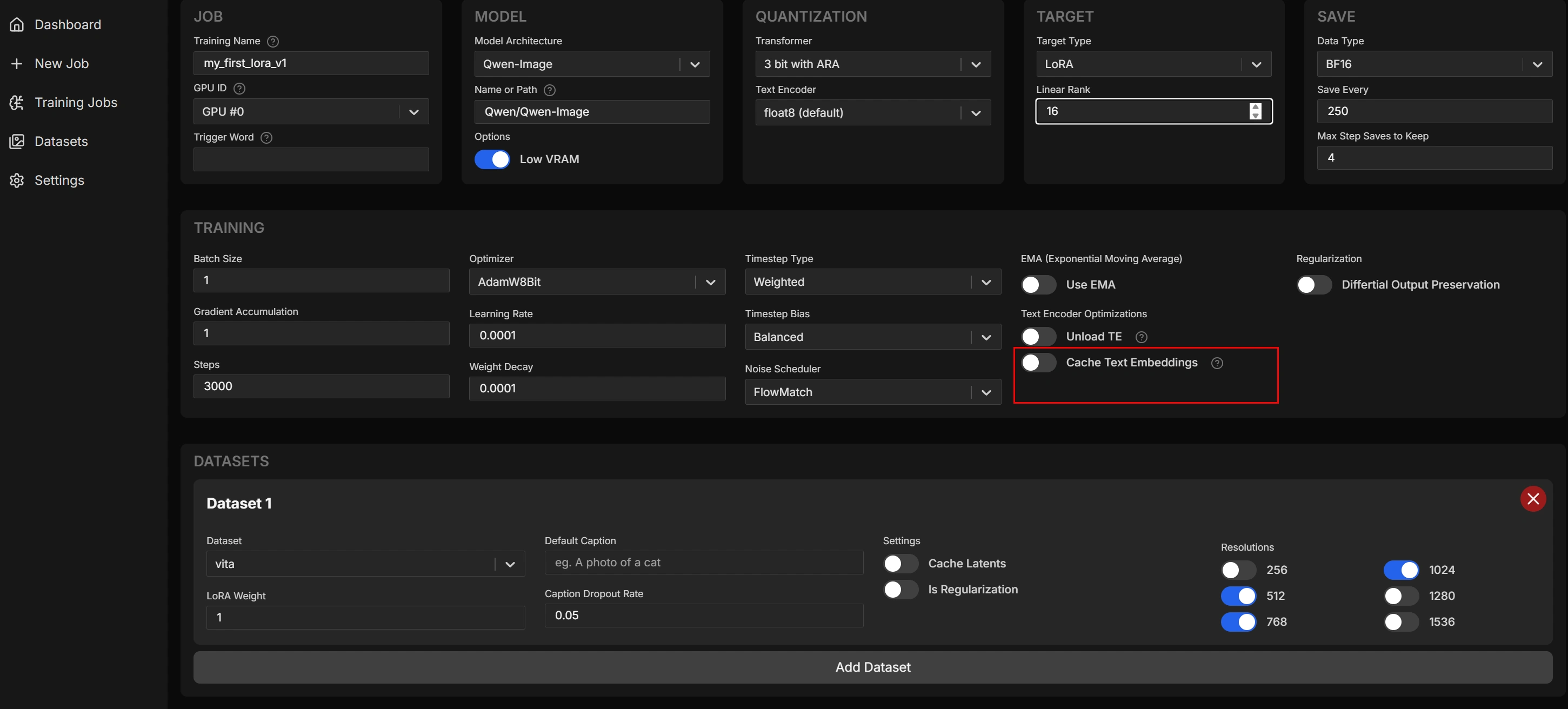

 10 Step(生成28秒 初期10だったので最低ラインです)
10 Step(生成28秒 初期10だったので最低ラインです)
 20 Step(生成49秒)
20 Step(生成49秒)
 30 Step(生成73秒)
30 Step(生成73秒)
 40 Step(生成94秒)
40 Step(生成94秒)
 50 Step(生成時間メモリ忘れました)
50 Step(生成時間メモリ忘れました)

 8step
8step

 8step
8step

 8step
8step

