C# WPFでQwen3を直接動かすだけ(LLamaSharp)
· 約4分

ドキュザウルス3.9へアップデートしたのでエラーがないか確認も兼ねたくそ記事です。
独立して動かせるならUnityで完全自立型のデスクトップマスコット作れそうですよね。
ヴィタちゃんデスクトップマスコットAIを作るしかないか?
LLamaSharpを使用
LLamaSharpとLLamaSharp.Backend.CpuをNugetでインストール
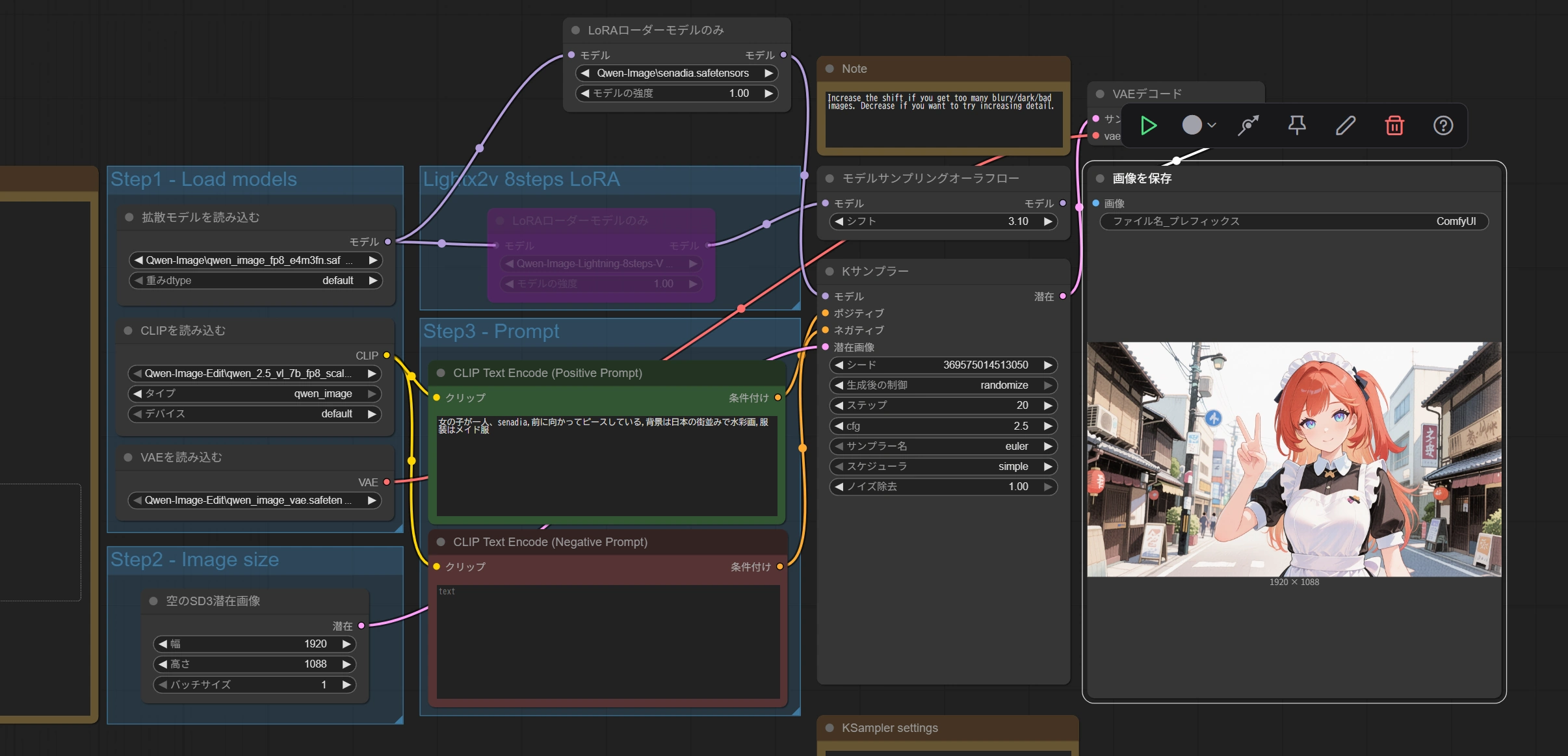
使用モデルと環境
C# WPF .NET8 プロジェクト名[Qwen3_Demo]
Qwen3-0.6B-GGUF
Qwen3-1.7B-GGUF
modelsフォルダを作成してダウンロードしたモデルを保存してください。(モデルは常にコピーでいいです)
ggufなのでLMStudioのモデルコピーしてきても動きました。(gemma3)
- CPU i7-1165G7(テスト用PC)
- メモリ 16GB
- GPU iRISXe(ないようなもの)
特別なこともないのでソースコードは下に貼っておきます。
C# WPFでQwen3 0.6bを動かす
さすがCPUオンリーですね思考モードだとしても遅いです。
(Thinkingないモデルはそこそこ早かったですがCPUじゃたかがしれてます)
Qwen3 0.6bがいつのデータで学習されてるのかわかりませんが適当なこと書きすぎ・・・
Qwen3 1.7bの場合
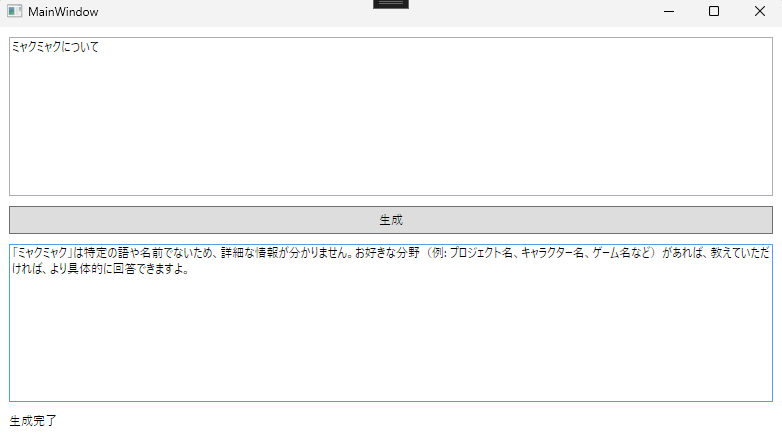 やっぱり1.7bは欲しいですねこう見ると
やっぱり1.7bは欲しいですねこう見ると
っていうと8bそして14bほしくなるのでGPUは必須です。
おそらく14-20bがデスクトップマスコット作るなら上限ですレスポンス速度が命なので
全体的なコード
MainWindow.xaml[クリックして展開]
<Window x:Class="Qwen3_Demo.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:local="clr-namespace:Qwen3_Demo"
mc:Ignorable="d"
Title="MainWindow" Height="450" Width="800">
<Grid>
<Grid Margin="10">
<Grid.RowDefinitions>
<RowDefinition Height="*"/>
<RowDefinition Height="Auto"/>
<RowDefinition Height="*"/>
<RowDefinition Height="Auto"/>
</Grid.RowDefinitions>
<TextBox x:Name="InputTextBox"
Grid.Row="0"
TextWrapping="Wrap"
AcceptsReturn="True"
VerticalScrollBarVisibility="Auto"/>
<Button x:Name="GenerateButton"
Grid.Row="1"
Content="生成"
Margin="0,10"
Padding="20,5"
Click="GenerateButton_Click"/>
<TextBox x:Name="OutputTextBox"
Grid.Row="2"
TextWrapping="Wrap"
IsReadOnly="True"
VerticalScrollBarVisibility="Auto"/>
<TextBlock x:Name="StatusText"
Grid.Row="3"
Margin="0,10,0,0"
Text="準備中..."/>
</Grid>
</Grid>
</Window>
MainWindow.xaml.cs[クリックして展開]
using System.IO;
using System.Text;
using System.Text.RegularExpressions;
using System.Windows;
using LLama;
using LLama.Common;
namespace Qwen3_Demo
{
public partial class MainWindow : Window
{
private string _modelPath = "models/Qwen3-0.6B-Q8_0.gguf";
private CancellationTokenSource? _cts;
public MainWindow()
{
InitializeComponent();
CheckModel();
}
private void CheckModel()
{
if (File.Exists(_modelPath))
{
StatusText.Text = "準備完了";
GenerateButton.IsEnabled = true;
}
else
{
StatusText.Text = "モデルファイルが見つかりません";
MessageBox.Show($"モデルファイルが見つかりません: {_modelPath}");
}
}
private async void GenerateButton_Click(object sender, RoutedEventArgs e)
{
if (string.IsNullOrWhiteSpace(InputTextBox.Text))
{
MessageBox.Show("入力テキストを入力してください");
return;
}
_cts?.Cancel();
_cts = new CancellationTokenSource();
GenerateButton.IsEnabled = false;
StatusText.Text = "生成中...";
OutputTextBox.Text = "";
try
{
var userInput = InputTextBox.Text;
await GenerateTextAsync(userInput, _cts.Token);
StatusText.Text = "生成完了";
}
catch (OperationCanceledException)
{
StatusText.Text = "キャンセルされました";
}
catch (Exception ex)
{
MessageBox.Show($"エラー: {ex.Message}");
StatusText.Text = "エラー";
}
finally
{
GenerateButton.IsEnabled = true;
}
}
private async Task GenerateTextAsync(string userInput, CancellationToken cancellationToken)
{
var parameters = new ModelParams(_modelPath)
{
ContextSize = 4048,
GpuLayerCount = 0,
BatchSize = 512
};
using var model = LLamaWeights.LoadFromFile(parameters);
using var context = model.CreateContext(parameters);
var executor = new InteractiveExecutor(context);
var chatPrompt = BuildQwenPrompt(userInput);
var settings = new InferenceParams
{
MaxTokens = 1024,
AntiPrompts = new List<string> { "<|im_end|>", "<|im_start|>" }
};
var fullText = new StringBuilder();
int tokenNum = 0;
await foreach (string text in executor.InferAsync(chatPrompt, settings, cancellationToken))
{
if (cancellationToken.IsCancellationRequested)
break;
fullText.Append(text);
tokenNum++;
// テキストを分離
var (thinkPart, answerPart) = SeparateThinkAndAnswer(fullText.ToString());
await Dispatcher.InvokeAsync(() =>
{
// 回答部分のみを表示
OutputTextBox.Text = answerPart.Trim();
// デバッグ用:think部分をステータスに表示
if (!string.IsNullOrEmpty(thinkPart))
{
StatusText.Text = $"生成中... ({tokenNum} tokens) [思考中]";
}
else
{
StatusText.Text = $"生成中... ({tokenNum} tokens)";
}
});
if (tokenNum >= 1024)
break;
}
}
private (string thinkPart, string answerPart) SeparateThinkAndAnswer(string fullText)
{
// <think>...</think> を抽出
var thinkMatch = Regex.Match(fullText, @"<think>(.*?)</think>", RegexOptions.Singleline);
var thinkPart = thinkMatch.Success ? thinkMatch.Groups[1].Value.Trim() : "";
// <think>タグを除去した部分を回答とする
var answerPart = Regex.Replace(fullText, @"<think>.*?</think>", "", RegexOptions.Singleline);
// 未完了の<think>タグも除去
answerPart = Regex.Replace(answerPart, @"<think>.*", "", RegexOptions.Singleline);
return (thinkPart, answerPart.Trim());
}
private string BuildQwenPrompt(string userMessage)
{
//thinkタグを消すため(要調性)
return $"<|im_start|>system\nあなたは親切なAIアシスタントです。<think>タグは使わずに、直接答えてください。<|im_end|>\n<|im_start|>user\n{userMessage}<|im_end|>\n<|im_start|>assistant\n";
}
}
}



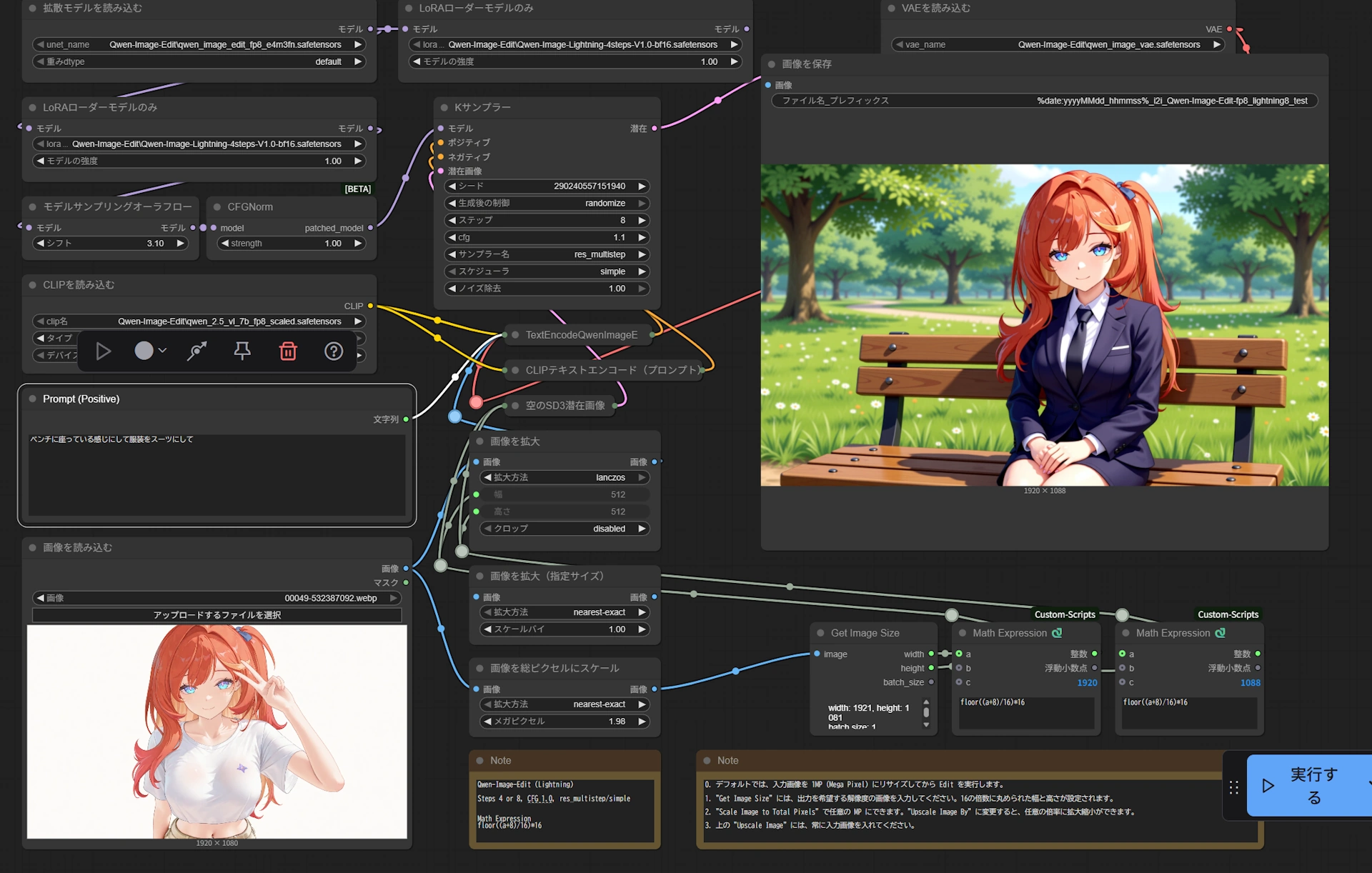
 10 Step(生成28秒 初期10だったので最低ラインです)
10 Step(生成28秒 初期10だったので最低ラインです)
 20 Step(生成49秒)
20 Step(生成49秒)
 30 Step(生成73秒)
30 Step(生成73秒)
 40 Step(生成94秒)
40 Step(生成94秒)
 50 Step(生成時間メモリ忘れました)
50 Step(生成時間メモリ忘れました)

 8step
8step

 8step
8step

 8step
8step


 ↑プロンプト(白いワンピースの女性がひまわり畑に一人,麦わら帽子をかぶっている,る,momijiina_style,vita20250824)
↑プロンプト(白いワンピースの女性がひまわり畑に一人,麦わら帽子をかぶっている,る,momijiina_style,vita20250824)
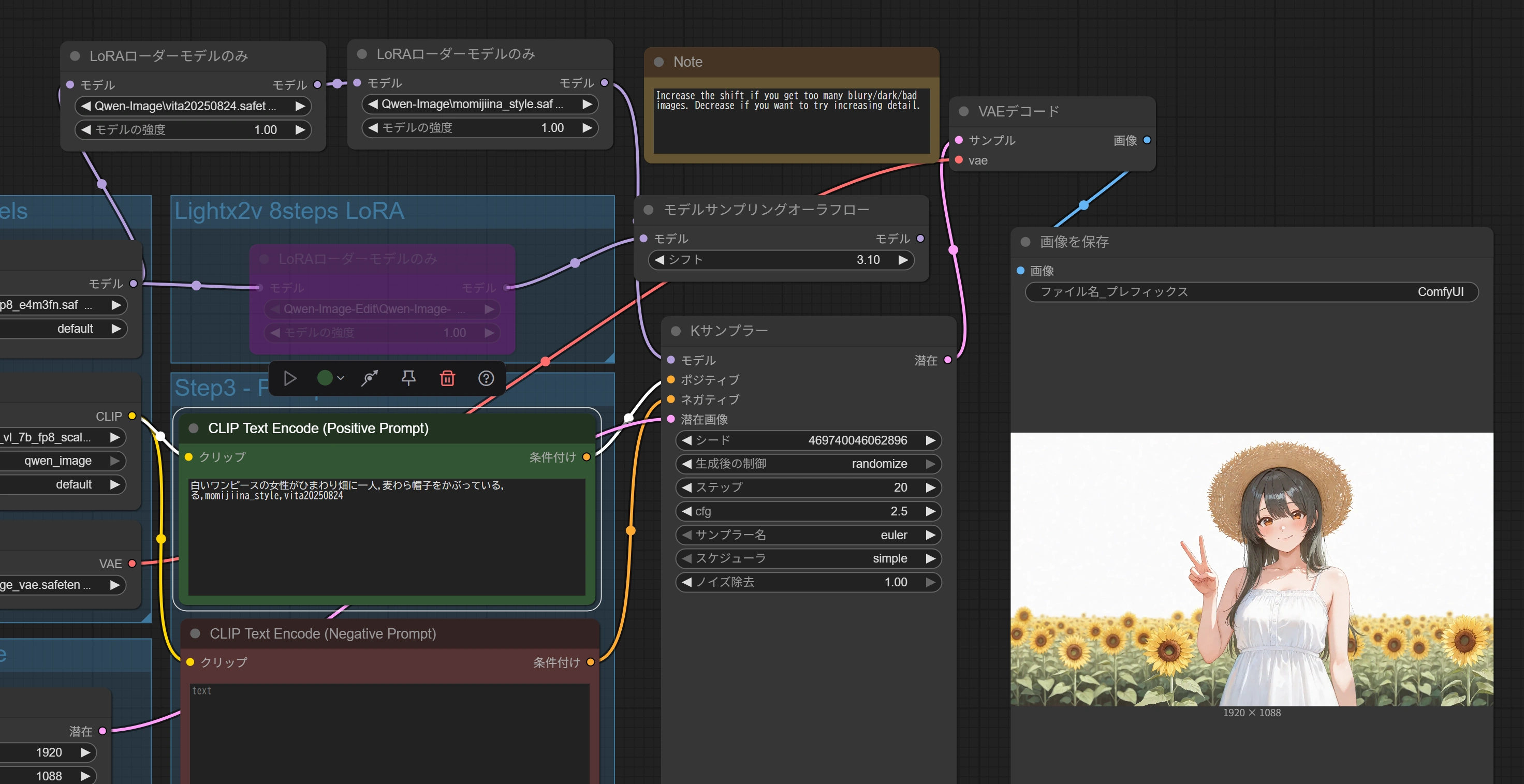





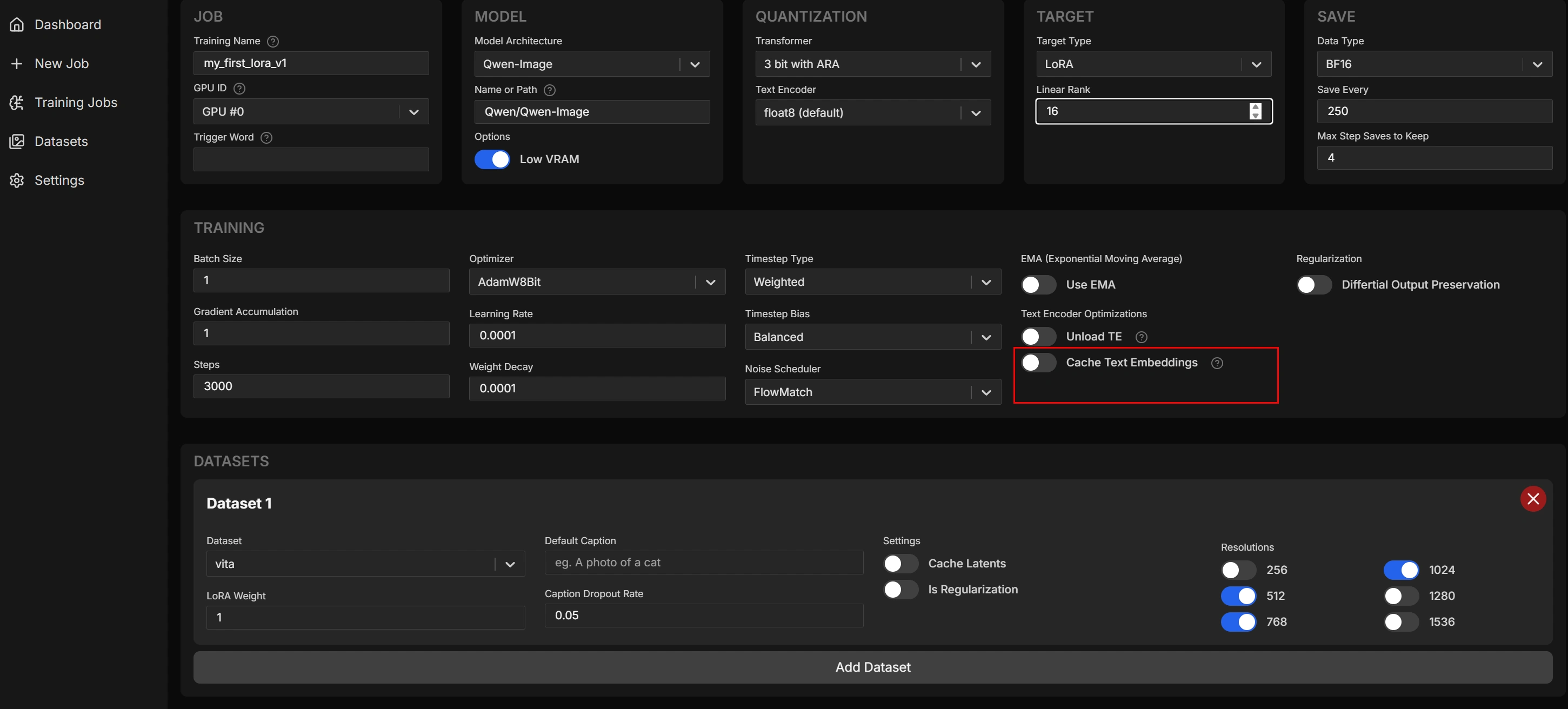
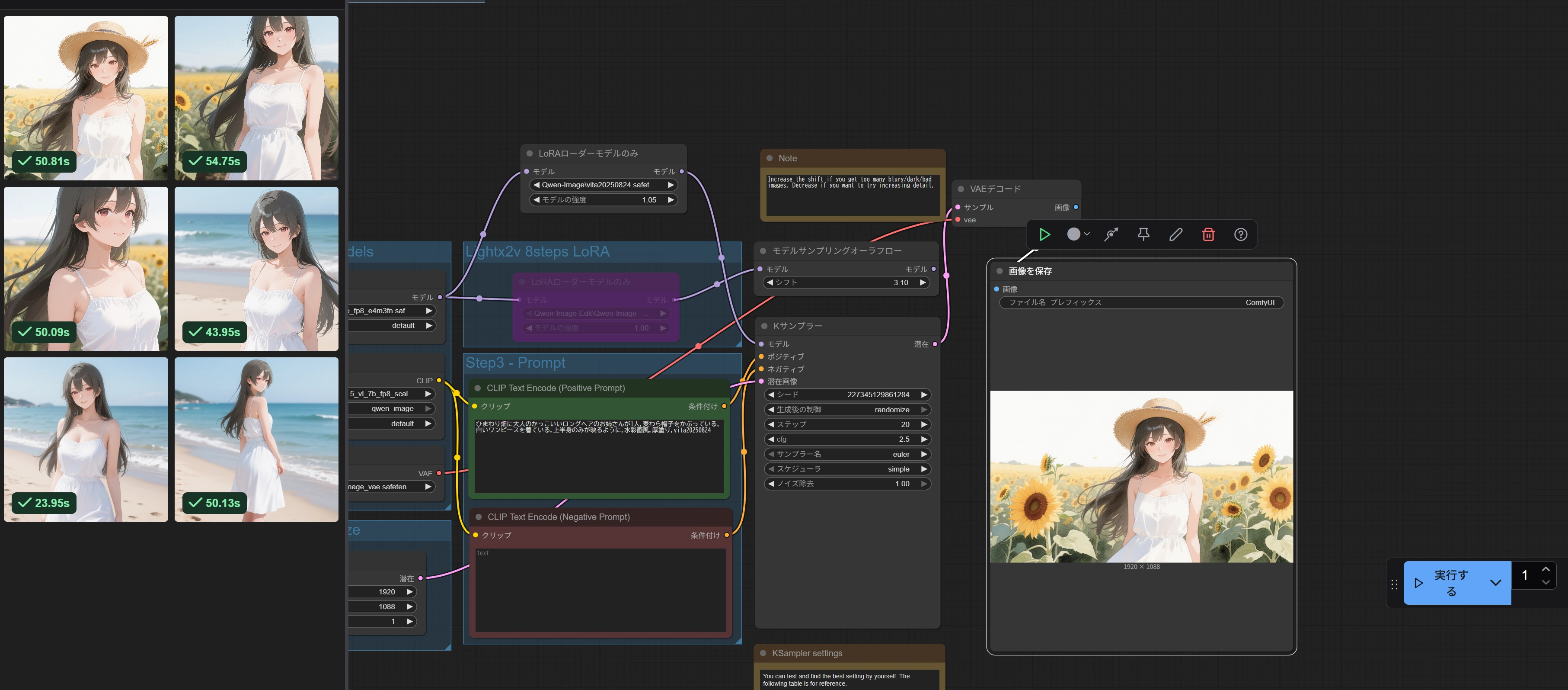 (プロンプトなど色々試していくうちに生成時間は平均50秒くらいになりました。)
(プロンプトなど色々試していくうちに生成時間は平均50秒くらいになりました。) (Stable Diffusionで作りました)
(Stable Diffusionで作りました)